
Building the world’s fastest website analytics
technical Jack Ellis · Mar 30, 2021In March 2021, we moved all of our analytics data to the database of our dreams.
For over a year, we'd been struggling to keep up with our analytics data growth. Fathom had been growing at the speed of light, with more and more people ditching Google Analytics, and our data ingestion had been going through the roof. Our popularity has been great for business and user privacy, but it wasn't good for dashboard performance. What we had wasn't working for us.
I often see engineers write about various migrations they've performed, but they always focus on just the technology. Here's a pro, here's a con, and here's another pro. But it's boring. So in this blog post, I'm going to give you one of the most transparent write-ups into what it's like to run a high-risk, high-stress migration. I'm going to take you behind the scenes, where I'll share our challenges, research, sabotage, and a happy ending.
Our database history
Version 1
When we first built Fathom on Laravel, we decided to roll with Heroku. I've spoken about this in-depth before, so I won't go into detail, but I decided that a Postgres database would be the best choice since Heroku offered it as a service managed by them. It wasn't just an add-on service; it was one they had committed to providing "officially." In hindsight, this was a mistake because I had no experience with Postgres.
Version 2
For Version 2, we rebuilt Fathom Analytics from the ground up and moved to Laravel Vapor. We kept a similar database structure but moved to managed MySQL. The upside was that I was back in my comfort zone (where I had experience), but the downside was that we did nothing to improve our database structure. Were things faster? Sure. We had increased CPU & RAM, and queries performed better, but this wasn't a sustainable solution for our dashboard or wallet.
The problems with MySQL
Before I list out the reasons for moving away from MySQL, I want to loudly state that I know MySQL wasn't made for this high-scale, analytical use case. With that cleared up, here are the main reasons we needed to move away from RDS for MySQL:
Bad performance
Despite keeping summary tables only (data rolled up by the hour), our database struggled to perform SUM and GROUP BY. And it was even worse with high cardinality data. One example was a customer who had 11,000,000 unique pages viewed on a single day. MySQL would take maybe 7 minutes to process a SUM/GROUP query for them, and our dashboard requests would just time-out. To work around this limitation, I had to build a dedicated cron job that pre-computed their dashboard data.
We needed more flexibility
For Version 3, we've gone all-in on allowing you to drill down & filter through your data, meaning we're keeping 1 row for each pageview. If MySQL can't handle summary table aggregations at medium scale, how on earth would it handle this new approach, where we have hundreds of millions of rows for a single website?
IOPS
With RDS, we had to think about IOPS. After a stressful experience with a viral website, we started over-provisioning IOPS heavily for RDS. And it's expensive. If you're not familiar with IOPS, the simplest way to explain it is that you have to provide a certain amount of storage, which comes with a fixed amount of IOPS, which dictates your maximum read/writes per second to your database. And if you get a viral site come in, and you don't have the appropriate IOPS to handle it, welcome to backlog town, population you.
To ensure we could handle traffic floods, we've been paying for 2,000 GB of database storage. This gave us 6,000 IOPS, which was suitable for us. So we were paying an extra $500/month for storage we didn't need, just in case we had another viral site we needed to handle. And at the time of writing, we're still paying for this because AWS doesn't let you downgrade your storage easily. (Yes, I'm salty about this.)
Connection limit
Connection limits are an area that I've always been concerned about. With the new solution we choose, I want it to handle many thousands of connections with ease, without us having to spend a fortune.
Our search for a new friend
We were clear about why we wanted to leave MySQL behind, and we knew there were better-suited database solutions on the market. Before we started searching, we discussed our non-negotiables:
- It must be ridiculously fast
- It must grow with us. We don't want to be doing another migration any time soon
- It must be a managed service. We are a small team, and if we start managing our database software, we've failed our customers. We're not database experts and would rather pay a premium price to have true professionals manage something as important as our customers' analytics data
- It must be highly available. Multi-AZ would be ideal, but high availability within a single availability zone is acceptable too
- Cost of ownership should be under $5,000/month. We didn't want to spend $5,000 off the mark, as this would be on top of our other AWS expenses, but we were prepared to pay for value
- The software must be mature
- Companies much larger than us must already be using it
- Support must be great
- Documentation must be well-written and easy to understand
I tried a few solutions. And honestly, my reason for not choosing a service was seldom related to performance alone. For me, I want the whole package. I like speed, but I also want to feel good about what I'm using. I want the people we're working with to be good people. And the technology has to fit into my existing knowledge in some way so that the learning curve isn't too large.
ElasticSearch
We started with ElasticSearch, as it looked like it would deliver nearly everything we needed. The documentation wasn't easy for me to understand, and I found it so stressful to use. Fortunately, my friend Peter Steenbergen spent a ton of time teaching me everything about Elasticsearch. He's one of the nicest guys I've ever met, and he is an Elasticsearch genius. Thanks for everything, Peter.
After a lot of learning from Peter, we had Elastic ready to go, and we were a few weeks away from going live. But then I chickened out. I hadn't considered how much of our application I was going to need to refactor. Everything is written in MySQL. Processing page views was one thing, but I would have to alter our email reports, data exports, monitoring, dashboard queries, automated testing and more.
Additionally, and I can't put my finger on this, Elasticsearch just felt wrong. I had managed to rebuild everything Peter showed me, but I felt nervous using it. This JSON approach and way of querying didn't feel good; high cardinality queries weren't performing as fast as I wanted, and I was sure I could get faster performance elsewhere. Also, while Elasticsearch was able to handle our use case, I didn't feel like it was made for it. I knew there were other solutions out there that were dedicated to fast, real-time analytics. So my eyes started wandering.
TimescaleDB
I took a look at TimescaleDB because every time I tweeted about Elastic, some random people would reply talking about it. The technology looks fantastic and is built upon Postgres. However, after some time in the docs and reading about distributed hypertables, I felt overwhelmed, so I chickened out. No comments on their technology; I just didn't get to use it. I'm confident they would've also been a good solution had their software clicked with me.
InfluxDB
InfluxDB's pricing was, by far, the best pricing model I encountered. You don't need to provision anything; you pay for what you use. This was how we liked to do things, as we prefer things to be serverless, so I signed up and took a look at their documentation. It lasted about 10 minutes. The learning curve was huge, we'd have to do so much refactoring, and I didn't have the time to invest in learning about it. This happens a ton in my work. I will come across technologies, but I won't use them if they have a steep learning curve. From what I understand, InfluxDB is a brilliant piece of tech; it just didn't click for me.
Rockset
You don't have to put on the red light, Rockset. I had so much fun exploring Rockset. I was 100% convinced that Rockset was going to be the best thing ever and that I'd met the solution of my dreams.
Here's how it was going to work:
- We'd ingest data into DynamoDB, paying on-demand with unlimited, serverless throughput
- DynamoDB would stream to Rockset using DynamoDB Streams
- Rockset would let me query DynamoDB in any way I pleased, with speed and complete flexibility
I started fantasizing about the fact that we would never, ever have to worry about scaling servers. DynamoDB would just take it. I was giddy over the prospect of deploying this solution.
I tried Rockset two times, once in late 2020 and again in early 2021. I was blown away by the sync from DynamoDB to MySQL-like querying. It was everything I wanted.
So why didn't we go with Rockset?
In late 2020, on 8,000,000 records (a tiny portion of our data set), the aggregation query took two times as long as Elasticsearch (12 seconds vs 6 seconds). That alone made me question everything, and I started to get nervous. Once I'm getting nervous, it's hard to persuade me to stay. Rockset put a ton of attention on this and got the query down to 4-5 seconds. They worked on improving the speed of things by as much as an additional 2x more. But I stayed quiet because, even though they had done this, we had hundreds of millions of rows. Sure, they'd fixed things on our tiny data-set, but would it scale? I was nervous and churned out of my trial.
I returned in early 2021 and tried things again. This time we were able to improve query speeds significantly. We managed to get rapid queries, but the cost was something high, like $8,000/month (note: I forget the exact figure, as I have no record of the support chat). The person on support had tried to suggest we speak with engineers, but I wasn't feeling it, so I terminated my trial again. Am I the worst SaaS customer of all time?
I have no hard feelings towards Rockset, and I think they're an exciting company. After I left, Shawn reached out and said their team had taken a look at my queries from support and were confident they could bring in some significant performance & price improvements if I were willing. But once I get to the point where I'm backing away, I'm hard to reel back in.
ClickHouse
ClickHouse came up in conversation, of course. I know that Cloudflare is using it at scale. But Cloudflare is a multi-billion dollar giant with a team dedicated to managing infrastructure like that. We are Jack & Paul, with a few folks helping us. We needed a service operated by people who are as good or better than Cloudflare's in-house team.
ClickHouse does indeed offer a managed service, but a Russian company would control it. It felt like a business risk to rely on a Russian company because of the constant flow of sanctions. And at time of writing this, I've just read the following:
"Further sanctions are upcoming, as the United States assesses the Russian role in the massive SolarWinds cyber hack and allegations that Russia sought to interfere in the 2020 U.S. election and offered bounties to Taliban fighters to kill American soldiers in Afghanistan, the officials said."
Source: U.S. imposes sanctions on Russia over the poisoning of Navalny | Reuters
Politics can interfere with tech. GitHub was restricted from offering its full service to Iran since 2019. Slack started banning users from Iran back in 2018. The point is, politics can be a considerable business risk, and it's safer for us to stay in the West.
Athena
Athena is an incredible piece of technology. Scan through trillions of records using serverless compute, paying only for what you use? Amazing. But it was too slow. We'll be using this for our new security system we're building, as it's incredible, but it's not fit for fast analytics.
A wild Twitter advert appeared
So after doing so much research and hopping between tools, I was hit by an advert on Twitter. I'd been tweeting about analytics a whole bunch, so perhaps that was how this advert hit me. I have no idea. But there was the advert, and it stood out to me (I emailed them to get a hold of this graphic because it's so epic).

What the hell does this even mean? Well, it's a play on a sci-fi TV show from the 80s called Max Headroom. I've never heard of it, my boomer friends, but it certainly made me click because, yes, I had indeed maxed out MySQL.
The site felt super enterprise, and I was a little nervous clicking around. But I saw site copy like "real-time analytics," "operational analytics," and then "dashboard acceleration." And then saw "MySQL wire compatible." So I was getting excited by this. The pros it had going for it were that I wouldn't have to re-write any of my queries, and I would be able to keep Laravel query builder (used extensively throughout our application). This was a huge selling point.
I was also excited to see that companies like Comcast, Uber, Cisco, Samsung, Wayfair, Pandora, Monday.com and Intel were using it. Those companies have far more data than us, so we'd probably be one of SingleStore's smallest customers.
As I got further down the rabbit hole, I learned that SingleStore was a rebrand of MemSQL, a distributed database system launched in 2013. I've heard of MemSQL, but that was as far as my knowledge went. Regardless, I was curious, and the website was pushing me towards an introduction video.

I spent an hour watching this video, and I was blown away. They talked about the problems we were facing, and they seemed to have the solutions. They gave specific use cases that made me confident they could handle us:
- Comcast streaming 300,000 events per second
- Akamai handling 10,000,000 upserts per second
- A Tier-1 US bank handling real-time fraud protection with 50ms latency
We are not even close to this level of scale. If these companies are using SingleStore for that kind of scale, our use case should be a walk in the park. But even with all of this confidence, I had some doubt in the back of my mind. Sure, they're marketing that they can do all these fantastic things, but there's got to be a problem. The reality seldom lives up to the marketing hype. Regardless, I spoke to them on their live chat, and a member of their team (Savannah) followed up with me via email immediately. I dropped the ball a few times, but Savannah & Sarung (a solutions engineer) were adamant with their follow-up, and they booked me in for a call within 24 hours of me confirming a day.
The dreaded sales process
The first call was a casual meeting with Sarung and Savannah, where I got to speak about all of our problems, solutions we'd tried, solutions we were considering and what we wanted to achieve. I felt super confident right off the bat, as he told me that they deal with this kind of thing all the time. I liked this whole approach because, despite us being a tiny company, we still received direct attention and care. They were investing in the relationship. They enabled "proof of concept" mode on our account and committed to helping us get a concept built within 2 weeks. Amazing.
Off the back of that call, Sarung scheduled a meeting with Savannah and one of the SingleStore database engineers (Yuriy). So I suddenly had a call with an engineer who understood our needs and another engineer who helps build the technology itself. I was utterly blown away by the fact that they were investing so much upfront with zero commitment from me, and it felt so good. It reminds me of Gary Vaynerchuck's book: Jab, Jab, Jab, Right Hook.
Now we had this call on the calendar, I dove into the documentation and spent days reading it. I completely immersed myself in everything they had to offer, and it all felt super intuitive. I didn't want to waste time on the call, so I learned everything I could from the documentation, meaning I could ask them questions that were a little more specific or nuanced.
After spending a few days reading their documentation, I put together a big slideshow detailing how we do things, what we want to do, and some questions. The call was marvellous. Not only were they able to answer my questions, but they offered alternative approaches. Originally, I was adamant that we were going to perform the following conversion:
- page_stats -> page_stats_hourly, page_stats_daily, page_stats_monthly, etc.
- referrer_stats -> referrer_stats_hourly, referrer_stats_daily, etc.
And then the same with all the tables. The idea would be that we'd have improved performance because we roll it up even further. Anyway, I came away from the call feeling great, and I dove into finalizing the plans.
One day later, I had even more questions. We spoke multiple times over email, and then they offered me another call. Now you have to understand that I do not like sales calls, but this wasn't a sales call. This was a call where I could ask for help from engineers with 100x more knowledge than me, who have solved challenges for companies far larger than ours, who are effectively offering me thousands of dollars worth of consulting, completely free. It felt so good. And I must admit, I was feeling a little bit guilty. I'm not one to take, take, take, and not give anything in return. As soon as we finalized the last few pieces, I told them I was eager to sign a year-long contract for their managed service.
After signing, one of the biggest things I was worried about was that they wouldn't care about us anymore. You know how salespeople care so much at the start of a relationship, but once you sign a contract, they have no idea who you are. Well, in this case, the complete opposite happened. I fired off a few questions a week or so after signing, and they came back with answers directly from a skilled engineer. The final cherry on top for me was when I sent them our schema. We had finalized it internally. We were going live in less than two weeks and needed an expert eye. Sarung checked it himself but also had their VP of Engineering look at it. Are you kidding me?
There's no affiliate program, I'm not being paid to write this, but I believe that when a company is doing good for the world, we should write about it. In the same way that we put companies on blast when they do bad things, companies should also be amplified when doing good things.
The "sales process" came to a close. We were happy with everything, but now it was time to get serious about migration.
Database structure
This write-up was always going to be focused on migration, but I wouldn't forgive myself if I didn't share some details about how our database is set-up. We're using the COLUMNSTORE option, and it's fast.
We have three tables now: pageviews, events and event_properties.
Pageviews
The pageviews table is where we store, believe it or not, all pageviews. They come in via SQS in real-time, and we may be moving to insert them on the HTTP layer if it's fast enough. The table is sharded by SiteID and Timestamp, which is how searches can be done so unbelievably fast. For me, I have no idea how the sharding works; I know that I set the SHARD KEY, and SingleStore takes care of the magic. I also have KEYS set on all of the fields you can filter on to ensure our V3 filtering is nice and fast. The biggest mistake I made was that I kept the UPDATEs in our code (we update the previous pageview with the duration, remove the bounce, etc.). In a few weeks, I'll be moving to 100% append-only by utilizing negative numbers. For example, if you want to set bounce_rate to 0%, you would write a 1 for bounce_rate on the first pageview and then insert a duplicate with -1 for bounce_rate. And for the duplicate row, you'd have nothing set for pageviews, visits and uniques, so it would all group nicely.
Events & Event Properties
We haven't pushed events to the maximum yet, but we're confident with our decision. We shard on UUID, and then we set SiteId as the sort key. We do this because we want to utilize something called "local joins" in SingleStore. Long story short, events can be joined with event_properties (allowing you to have thousands of dynamic properties per event you track), and it's fast. And since we're going to be doing so much filtering in our dashboard now, we decided that this was the way to build it. And then we've also got KEYS for all the filterable fields.
For now, I'm not going to talk much about the technical side of SingleStore, as we've been using it less than a month. But if you'd like me to do a one-year review in the future.
Planning the migration
This isn't my first rodeo. I've migrated countless high-value projects in the past. And even within Fathom, we've already done multiple migrations. Our first migration was from multiple SQLite files, distributed across multiple servers, to a single Postgres database in the early days. Then our second was from Postgres to MySQL without downtime. But this migration was different because of the size of the data. We were dealing with hundreds of millions of rows, consisting of many billions of page views.
So let's talk about the data. The data we already had was split up across multiple tables. We had the following tables:
- page_stats
- referrer_stats
- site_stats
- browser_stats
- country_stats
- device_type_stats
Why was it done like this? Because we took a very radical approach when we first built Fathom that we shouldn't have this data tied together. We thought it was anti-privacy to do so. But after taking a good look at it in 2020, we realized that knowing what country, referrer, UTM tags, or browser a user came from wasn't an issue. The only piece we were concerned about was the browser version, as we felt it was too much information and useless for the majority of our customers.
We wanted to take all of the data we had and merge it into a single table: pageviews. Easy, right? Nope. Because if a single pageview had come in, we would have 1 row in each of the above tables. They were not linked together in any way, and somehow we needed to merge all of these tables into one without duplicating data while still supporting the dashboard summary views we needed. Yikes.
Since this blog post is all about nerding out, here's an example of the problem. Imagine you visited https://usefathom.com/pricing. That would come into our system as one pageview, but then we'd insert six different rows (one into each of the tables above).
After a ton of trial and error, I landed on a solution that would work beautifully. We could insert seemingly "duplicate" data but then filter out "irrelevant" data on the dashboard. For example, if we took all six rows from above and put them in a single table, SUM(pageviews) would return 6, even though we only dealt with one pageview. Well, each table has unique fields. For example, when we migrate a browser_stats entry, it will have pageviews, visits, and browser_id. And referrer_stats would have referrer_hostname and referrer_pathname. And the rest would all be similar. So all we had to do was migrate them pretty much as-is and then add a simple condition on our dashboard for each of the boxes. So with the Referrer Stats aggregate query, we simply needed to perform the SUM, but we would add WHERE referrer_hostname IS NOT NULL, meaning it would filter out the duplicates from tables that aren't referer_stats. Then we'd repeat the same with all tables. The only challenge we had was with site_stats because, moving forward, we would have no way to distinguish between page_stats and site_stats. So I simply added a custom value for "pathname" and set it to "SITE_STATS_MIGRATION." This meant that when we did our Page Stats aggregation query, I could add WHERE pathname <> 'SITE_STATS_MIGRATION'. Nice and simple. And remember, moving forward, we're storing one pageview per pageview, so this solution is also future proof.
The migration code
Many engineers across the world will use cloud ETLs to accomplish this. I know that there's AWS Glue which can do things like this. But for me, I like simple. I've never used AWS Glue, and since I was already uncomfortable with this migration, I wanted to stick with Laravel, background jobs and a GUI.
After multiple iterations, we landed on some code that worked beautifully. I've shared the base file along with an example of how we migrated one of the tables (browser_stats).
MigrateBase.php
<?php namespace App\Jobs\Migrate; use Illuminate\Bus\Queueable;use Illuminate\Contracts\Queue\ShouldQueue;use Illuminate\Foundation\Bus\Dispatchable;use Illuminate\Queue\InteractsWithQueue;use Illuminate\Queue\SerializesModels;use Illuminate\Support\Arr;use Illuminate\Support\Facades\Cache;use Illuminate\Support\Facades\DB; class MigrateBase implements ShouldQueue{ use Dispatchable, InteractsWithQueue, Queueable, SerializesModels; protected $startId; protected $endId; protected $data; /** * Create a new job instance. * * @return void */ public function __construct($startId, $endId) { $this->startId = $startId; $this->endId = $endId; } public function migrateData($key, $callback) { $migrationActive = retry(30, function() { return Cache::get('migration_active', false); }); // When there are zero rows or if the migration is canceled, we bail. if ($this->data->count() == 0 || ! $migrationActive) { return true; } $callback(); // Returns the last ID to be processed $nextId = $this->data->last()->id; retry(30, function() use ($nextId, $key) { Cache::put($key, $nextId); }); $class = get_called_class(); // Onto the next one retry(30, function() use ($nextId, $class) { dispatch(new $class($nextId, $this->endId)); }); }}MigrateBrowserStats.php
<?php namespace App\Jobs\Migrate; use App\Jobs\Migrate\MigrateBase;use Illuminate\Support\Arr;use Illuminate\Support\Facades\DB; class MigrateBrowserStats extends MigrateBase{ public function handle() { $this->data = retry(30, function() { return DB::table('browser_stats') ->selectRaw('id, site_id, browser_id, pageviews, visits, `timestamp`') ->where('id', '>', $this->startId) ->where('id', '<=', $this->endId) ->orderBy('id', 'asc') ->limit(30000) ->get(); }); $this->migrateData('progress:browser_stats', function() { $browsers = DB::table('browsers')->get()->pluck('name', 'id')->toArray(); $inserts = $this->data->map(function($row) use ($browsers) { return [ 'site_id' => $row->site_id, 'timestamp' => $row->timestamp, 'pageviews' => $row->pageviews, 'visits' => $row->visits, 'browser' => Arr::get($browsers, $row->browser_id), ]; })->toArray(); retry(5, function() use ($inserts) { DB::connection('singlestore')->table('pageviews')->insert($inserts); }); }); }}A few points about the way I wrote the code:
- The MigrateBase file checked the cache key "migration_active" because I had a big, red button on a GUI that allowed me to abort the migration at any moment
- The reason I made the job dispatch itself recursively is that I didn't want to take our databases offline with too many concurrent jobs. Even doing it this way, our target database was running at 100% CPU, handling 30,000+ records a second ingest
- You'll notice how I did a manual lookup for $browsers instead of doing a join. This is because the performance was far better this way. I originally had joins, and they were causing big problems.
- Nearly everything is wrapped in retries. This is how I code. I assume there are going to be errors with external services, so I always try to wrap retries
You'll also notice $this->startId and $this->endId. We'll talk more about that in a later section.
Migration risks
Many years ago, I read something from Tim Ferris where he recommended imagining the worst possible case scenario for something, and then keep asking "and then". I use this technique for risk management in many areas of life and business, and I apply it to migrations too.
I could make a mistake on the new pageview processor
Solution: Ensure you've got the same tests we currently have, plus more. Even if it adds an extra day to migration, your number one priority is your test coverage
SingleStore may not be able to take all the dashboard queries
Solution: It seems that the limit is 100,000 by default (lol)
What if we've missed some blatant data inaccuracies?
Solution: Write a script to compare test-migrated data to old data. This will ensure we're good. Nothing complex, just compare site totals. If we do find out we migrated data wrong, we can just re-migrate historical data (aka all data without a client_id)
What happens if SingleStore goes offline?
Solution: Failed jobs table is important.
The migration plan
Before I get into details about the migration, here's the exact migration plan we followed. It didn't start like this. We had to adapt as we went through the days, but the point I want to illustrate is that a big migration isn't typically a single day of work. It spans multiple days. I don't expect you to follow all of this, as it's very specific to our application, but I want to give you an idea of how a typical migration plan looks for us:
8th & 9th March
- Delete test SingleStore cluster & re-create it as a larger instance
- Add the insert into SingleStore to production to hit a test table in SingleStore (for load testing)
- Monitor nodes and observe performance
- The way we currently track bounces won't work, as it will always be one session and one bounce. We need only to mark a pageview as a bounce if they're a NEW VISITOR. Else they aren't a bounce. We also need to ensure we are tracking the "exit rate" of a page. This is a separate metric, and we need to add it to our schema.
- Modify "bounce_rate" to use the isNewVisitor logic.
- Still make sure we update the previous pageview as bounces = 0 on a 2nd pageview
- Need to write tests for bounces to ensure it's done correctly, as tests didn't catch this
- Exits
- Import new schema as it contains exits and referrer_type
- Write tests for exits
- Disable cleanup crons temporarily
- Check what happens if SingleStore has an error. The migration scripts took AGES to fail, which was problematic. But it's likely a problem with my retry() wrap
- Important: We NEED to round timestamps down to the start of the minute to ensure we can't match anything from our temporary IP logs to the pageviews table.
- Referrer groups
- Add functionality to ProcessPageviewV3 to match referrers to a Group like we currently have
- Port it to MigrateReferrerStats (heh turns out it's already there)
10th March & 11th March
- Make a new config variable called "analytics_connection" and env variable called ANALYTICS_CONNECTION.. Have it on all environments, even data-export, and use it to establish which code to run in production. Values are either MySQL or SingleStore. This allows an easy switch
- Switch bounce rate back to 30 minutes
- Disaster recovery set-up
- Add column called in_singlestore (boolean), defaults to 0, to MySQL
- Modify aggregator so it won't read pageviews where in_singlestore = 1. We can modify that if we need to do disaster recovery if we end up needing to aggregate them (emergency only)
- Write test in ProcessPageviewRequestV3 to make sure it inserts into MySQL
- Run every single ProcessPageviewRequestTest test on the new processPageviewRequestV3 class. Good news, they all returned perfectly.
- We are now using a configuration variable to manage this stuff. So basically, we need to be checking the config variable to decide what to do. Lots of IF statements.
- Modify delete site cron so it doesn't chunk it and does it all in one query (we can do that now)
- Bring in all the queries from staging and make sure it reads pathname_raw
- ?refs are ignored and just kept as referrer stats
- Modify the PageStats/ReferrerStats scripts for the big German customer. They currently have custom code to hit a different table (top 300). Don't need that anymore (woohoo)
- Make sure everything that reads off of the following tables has been refactored to use SingleStore
- pageviews
- site_stats
- page_stats
- referrer_stats
- browser_stats
- country_stats
- device_type_stats
- Double check all of the tables again, haha.
- Final check on how the MigrateRefererStats visits works to ensure we do it right
- Did we catch the pageviews script install check
- Deploy master branch to staging & change env value to allow us to test
- Start migrating all data across up to a recent ID from an hour that is "unmodifiable".
12th March (late day for Jack)
- Wait for migration to finish
- This is the most important step of all time because it aims to detect any problems before we even go live with it. Because it's actual tests.
- Write a script that compares data on all accounts (site_stats, referrer_stats, page_stats, etc.), and then reports if there are any significant differences. The comparisons that are hyper important, as storage method has changed:
- Old bounce rate (old formula) vs old bounce rate (new formula) vs new bounce rate
- Old avg duration (old formula) vs old avg duration (new formula) vs new avg duration
- Write a script that compares data on all accounts (site_stats, referrer_stats, page_stats, etc.), and then reports if there are any significant differences. The comparisons that are hyper important, as storage method has changed:
- Fix countries
- Tests for SingleStore Data export. Basically, make it so that if the site is 849 (our site), use SingleStore for data source
- Run a SUM() on all tables up to those MAX IDs below, and compare the total pageviews to what we have in Singlestore
- Change TrafficController to use ProcessPageviewRequestV3 and then deploy codebase to the collector
- Run the query SELECT COUNT(*) FROM pageviews WHERE in_singlestore = 0. When this returns 0, we are ready to move to the next step
- Double check that no pageviews marked as in_singlestore = 1 are disappearing (aka still being processed), the same applies to the backlog
- Once all is clear, we will migrate from these IDs up until the most recent IDs in the stats tables, ensuring everything is fully in sync between Singlestore & MySQL
- Browser Stats: 1034645974 -> 1042809734
- Country Stats: 1001900052 -> 1010055546
- Device Type Stats: 1043096454 -> 1051261386
- Page Stats: 1032202277 -> 1040334477
- Referrer Stats: 359518504 -> 361922566
- Site Stats: 1060744259 -> 1068876508
- In all environments (production, collector and data-export), change DB_ANALYTICS_CONNECTION to singlestore and then re-deploy
- Disable the following cron jobs
- fathom:extract_top_300
- fathom:aggregate (woohoo)
13th March
- Test email report as it goes out tomorrow
17th March
- Deprecate MySQL completely and clear out old data
- Start working on reading "Current visitors" from SingleStore, not DynamoDB
- Goal stats migration & refactor
- Create goal tables in SingleStore
- Migrate goal_stats up to a sensible point (0 -> 19933106)
- Modify code, so it reads goal_stats and goals separately, allowing us to use MySQL for goals and SingleStore for goal_stats
- Modify all code to use SingleStore's new structure for goal_stats. It should be nice and easy since we already broke it up.
- Test data export locally
- ProcessEventRequest will only do inserts now, no updates / on duplicate key updates. No extra data needed yet, just what we have right now. Will need to load site_id, etc. too.
- Change schema to rename completions to conversions
- Modify goal stats migration to use conversions instead of completions
- Re-import 0 - 19933106
- Write tests for ProcessEventRequest
- Final review of all goal code changes
- Deploy everything to production
- Once production is deployed, deploy to collector immediately
- Migrate goal starts from 19933106 to the latest ID in goal_stats
18th March
- Clean up technical debt
- Write code to drop group from sites table (HAHA YES!)
- Re-enable the following cron jobs
- fathom:prune_deleted_sites
- fathom:prune_deleted_goals
- Write prune deleted goals function
Pre-migration
When I do a migration, a common method I adopt is migrating all "practically immutable data" ahead of time. So for this migration, I migrated all data up until -2 days ago. Why this? Because data from 2 days ago won't change, meaning it's safe. And the beauty is that, by doing this, the bulk of the migration is already done before we even get started.
When migrating the initial data, I manually grabbed end IDs (see $this->endId) for each of the tables, and I ran the migration using this professionally designed interface.
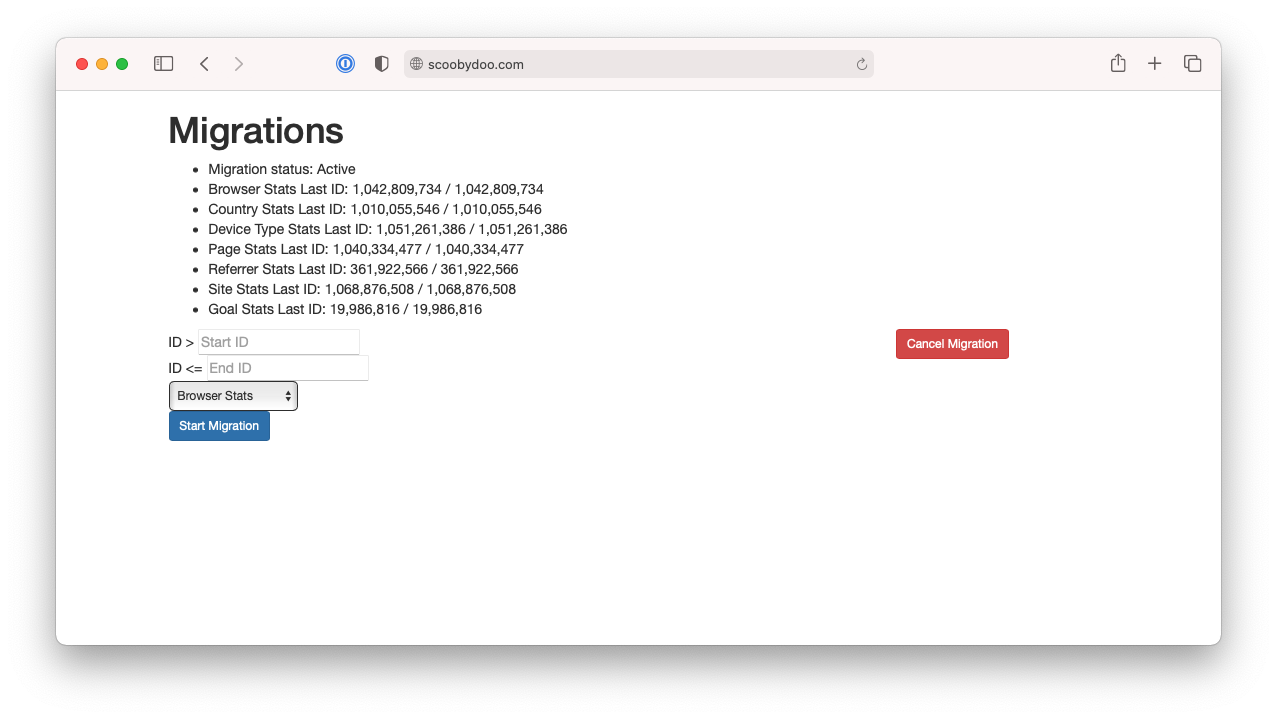
Look, I'm a GUI guy. Having an interface like this, with insight into migration progress and clear control over what I'm migrating, visually, makes me very happy.
So with this interface, I went through one table at a time via the dropdown, and the start Id would be 0, and the end ID would be an ID that I selected. And then I'd hit refresh every so often to see the progress in the list above. And it migrated across beautifully. In addition to the target database load, I had to be careful with IOPS. At the time, we still had many queries running our primary MySQL instance, and the last thing I wanted to do was destroy performance by running too much at once.
Migration day vs viral website
On migration day, we were feeling good. We'd been following the plan all week, discussing everything, and we were in a solid position. Hilariously, we had a site go super-viral on migration day, which meant that when I tried to migrate data from the previous ID up until a newer ID, we had a backlog that caused some problems, where dates for this one site were skewing my ability to extract a safe ID. We effectively had new and old data mixing in together. After making this mistake, I thought I'd made a huge mistake and that we'd have to restart everything, but then I realized that I could just delete the accidental data on the target database, and it would be like nothing ever happened.
I was running on about 8-12 shots of espresso, and I was still completely exhausted. My focus was so low, and I figured I must be super burned out, as the whole week had been such a grind. The coffee wasn't doing anything. By the time we got to the switch (aka the most important part of the migration), I had decided I wouldn't do it today. I was stressed & exhausted, and I would just put it off until tomorrow.
A few hours later, and after dealing with my toddler's bedtime tantrums for an hour, the data migration felt like it would be the easiest thing in the world, so I went ahead and finished it.
The key to switching between databases, and having no downtime, was the configuration variable and the "is_singlestore" column in all tables. It meant that we had an emergency fallback if required, and it would also stop any duplication of data.
Mission accomplished
After finishing the migration, we were partying big time. This was months of work, doing research, implementations, and so much more. We couldn't believe we were finally migrated into a database system that could do everything we needed and was ready to grow with us. I spent the next few days watching the server metrics to ensure nothing would go wrong, and it was beautiful.
Here and the benefits of our new set-up:
- We no longer need a dedicated data-export environment (Lambda provisioned with 10GB of RAM). We do our data exports by hitting SingleStore with a query that it will output to S3 for you typically within less than 30 seconds. It's incredible. This means we can export gigantic files to S3 with zero concern about memory. We would regularly run into data export errors for our bigger customers in the past, and I've spent many hours doing manual data exports for them. I cannot believe that is behind me. I'm tearing up just thinking about it.
- Our queries are unbelievably fast. A day after migrating, two of my friends reached out telling me how insanely fast Fathom was now, and we've had so much good feedback
- We can update and delete hundreds of millions of rows in a single query. Previously, when we needed to delete a significant amount of data, we had to chunk up deletes into DELETE with LIMIT. But SingleStore doesn't need a limit and handles it so nicely
- We used to have a backlog, as we used INSERT ON DUPLICATE KEY UPDATE for our summary tables. This meant we couldn't just run queries as soon as data came in, as you get into a DEADLOCK war, and it causes a lot of problems (believe me, had them). And the problem we had was that we had to put sites into groups to run multiple cron jobs side by side, aggregating the data in isolated (by group) processes. But guess what? Cron jobs don't scale, and we were starting to see bigger pageview backlogs each day. Well, now we're in SingleStore, data is fully real-time. So if you view a page on your website, it will appear in your Fathom dashboard with zero delays.
- Our new database is sharded and can filter across any field we desire. This will support our brand new, Version 3 interface, which allows filtering over EVERYTHING
- We are working with a team that supports us. I often feel like I'm being cheeky with my questions, but they're always so happy to help. We're excited about this relationship.
- SingleStore has plans up to $119,000/month, which is hilarious. That plan comes with 5TB of RAM and 640 vCPU. I don't think we'll get there any time soon, but it feels good to see they're comfortable supporting that kind of scale. They're an exciting company because they're seemingly targeting smaller companies like us, but they're ready to handle enterprise-scale too.
And as for price, we're spending under $2,000/month, and we're over-provisioned, running at around 10% - 20% CPU most of the day.
Sabotage
I was suffering from low energy in the two weeks leading up to this migration, and I was feeling awful throughout migration week, especially on migration day. On Sunday 14th March 2021, two days after we had finished the migration, my wife showed me an already-half-used bag of coffee beans I had been drinking through most of this migration, and the bag said "DECAF." Divorce proceedings are underway.
Conclusion
Performing a migration is such a high adrenaline, stressful task. You could make a mistake that causes you to lose data, and thousands of customers rely on you. Of course, you should have disaster recovery systems in place, but even having to trigger those is a bad outcome. I don't want to gloss over this. Migrations are often seen as being "just another day in the office," but they're not. If you're a CTO or work in some management capacity, please make sure you give your developers a few weeks off after performing a significant migration. Sure, keep them around for a few weeks after for bugs, but then make them take time off. Buy them a video game and tell them they can't come back to work until they've completed it ten times.
This whole process has been such an exhausting ride (especially without the help of caffeine), but it's been so very worth it. Hedonic adaption means that our new database is now the "new normal" to us, and we're used to how incredible it is. Right now, thousands of page views are coming in as I write this sentence, and I'm not worrying about backlogs because SingleStore can handle it all.
Looking for some Laravel Tips? Check out Jack's Laravel Tips section here.
You might also enjoy reading:

BIO
Jack Ellis, CTO + teacher
Recent blog posts
Tired of how time consuming and complex Google Analytics can be? Try Fathom Analytics: