
We rebuilt Fathom Analytics + moved to Laravel Vapor
technical Jack Ellis · Nov 29, 2019We’ve been sharing a lot about all the changes going on behind the scenes at Fathom recently. We spoke about how we built GDPR compliant website analytics, how we went from almost shutting down Fathom to tripling our MRR, and why we changed our pricing to focus on regular-sized businesses. But the most important changes we’ve made in our business have been completely rewriting our codebase twice and choosing the best (being the fastest and most resilient) infrastructure for the job.
In this article, we’re going to talk in-depth about our experience with Heroku and why we decided to move to Laravel Vapor. We’ll be covering the highs and lows and all the challenges we encountered with both platforms. And moving forward, we’ll look to share Vapor-related tips on our blog.
But before we dive into the infrastructure talk, let’s take things back to December 2018. Paul Jarvis, Fathom co-founder, was in a position where his partner in Fathom had just announced that he was leaving the development world. Paul is a competent developer but he certainly didn’t fancy maintaining a fleet of servers and a codebase he wasn’t familiar with. Luck would have it that his partner, Jack Ellis, who he worked with in another project, would jump at the opportunity to continue Fathom with him.
This is where the migration began. I (it’s me, Jack) came onto the project and things were set up in a way that I wouldn’t have chosen. This is a typical developer thing. We come into projects and decide that we want to change everything! But there wasn’t going to be a world in which I would be as productive with how things were set-up, nor would I commit to handling DevOps because I don’t need server stress in my life. Respect to anyone who lives on standby and puts out all of the server fires, you’re the real MVPs. But that’s not me.
Re-building V1 of Fathom Analytics’ application
The way V1 of Fathom was built was as follows:
- Billing Application
- 1 Database per customer, spread across a few VPS servers. And every customer had their own subdomain that linked to their database
This way of doing things is actually quite common, and there’s absolutely nothing wrong with it. But this wasn’t my preference, and I wanted everything centralized so that it would be easier to maintain. In addition to that, I didn’t want to manage any servers, because that’s less time spent coding. And VPS servers can and do go down for a multitude of reasons, far too often. Most sites can weather the storm but an analytics service needs high-availability.
With that in mind, I spun up a fresh copy of Laravel on my machine and began rebuilding Fathom from the ground up. Did I mention that Fathom was actually written in a language that I didn’t (and still don’t) program in? So the way I started building things was all done from the frontend, and then I filled in the gaps. I signed up to Fathom and began going through the billing interface, copying all of the HTML / CSS and then filling in the database / backend pieces myself. The billing interface was the easy piece, as I’d built these kinds of applications hundreds of times. Heck, I was building these kinds of applications back when I was 14, using Naresh’s User System from TechTuts (if you know, you know). So the billing part of things was written rather promptly.
Next, it was time to rebuild the dashboard. Paul had made some tweaks to the UI and he’d built the HTML / CSS for it (this is one of the reasons our partnership works so well, because he always codes his designs). Now, I’m not the kind of person that persistently pushes the use of SPAs (Single Page Applications) for everything. I grew up building SSR applications (CodeIgniter, Kohana, Laravel etc.) but the last chunk of my career has been predominantly with EmberJS. To me, it was obvious that this dashboard would thrive from being a SPA. So I spun up a fresh instance of EmberJS and began building Paul’s code in. V1 was very simple, so I dove right in.
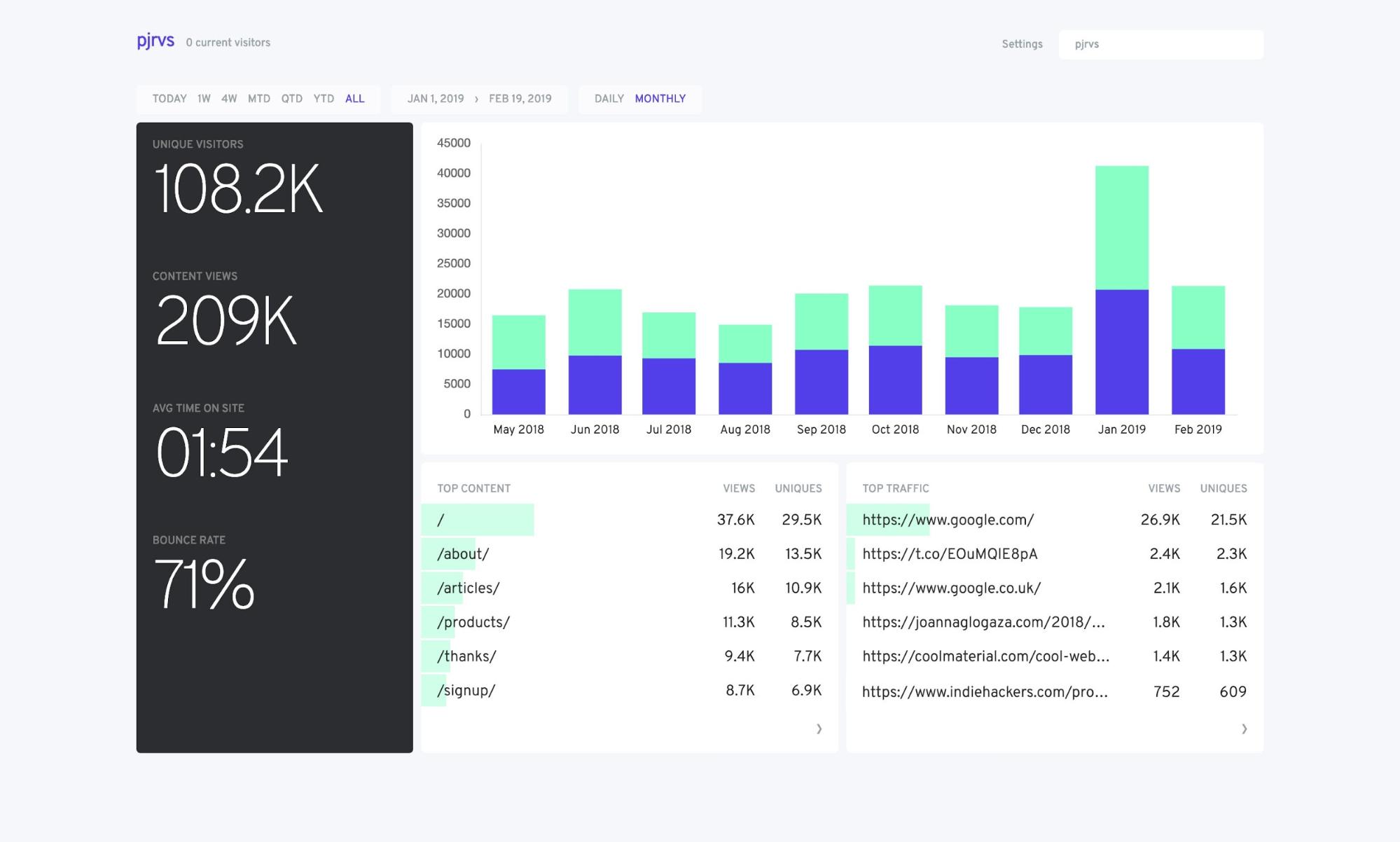
Building the display of the data was easy enough. I wrote the endpoints (well, for V1, I had a single endpoint that returned all the data. Not the best decision I’ve ever made). I had the dashboard built relatively quickly but then I had to handle the page view collector code.
The collection code was by far the piece I spent the longest on. The dashboard is far less important than the actual data collection. I was definitely up shit creek, but I had a paddle. The paddle I had was the previous, Go codebase. No, I didn’t write in Go, but it’s so similar to PHP that I was able to go through all the page view aggregation code and fully convert it to PHP. Now, for those of you reading this article and already opening up reddit & twitter to message us saying “WHY DID YOU USE PHP?!?!?!”… It’s the language we’re both most productive in, it’s come along way and it’s more than fast enough for our use case.
The biggest challenge with the pageview collection was building it in a way that scaled. We were processing millions of page views and we didn’t want our database to be smacked constantly, so we brought in a Redis queue. We spun this up on Heroku and it was bloody expensive, but it did a great job.
By the end of the re-development of V1, we were left with the following infrastructure set-up (this is a rough recollection, the set-up changed a few times)
- fathom-collector (our main pageview collection endpoint)
- 2 x STANDARD 2X Web Dyno (We previously ran 1 x PERFORMANCE M but we found that multiple STANDARD 2X was faster)
- 1 x STANDARD 1X Worker Dyno
- 1 x PREMIUM 0 Redis (used for queuing up page views for processing)
- fathom-billing (the standalone billing application)
- 1 x STANDARD 1X
- fathom-api (our Laravel API that the EmberJS dashboard digested)
- 2 x STANDARD 2X
- 1 x PREMIUM 1 Redis (used for queuing up aggregation)
- 1 x Premium 0 Redis (used for caching)
- 1 x STANDARD 1X Worker Dyno
And then these Heroku applications all shared a PREMIUM 0 Postgres Database. We paid for Premium because high availability was extremely important to us. Oh, and in addition to this, we ran our dashboard from Cloudfront / S3. It was a standalone EmberJS app that digested fathom-api.
So for those of you who know Heroku, you’re thinking “holy shit” as you count up how much this costs. This doesn’t include the standalone cron jobs we ran which were priced “on-demand”. What about when things went wrong and we had a backlog of queued pageviews we needed to aggregate? Yup, you guessed it, we had to spin up a bunch of extra queue workers to get through the backlog. Oh, you want us to share how much all of this cost us?
| Date | Cost |
|---|---|
| February | $517.79 |
| March | $834.34 |
| April | $467.65 |
| May | $478.50 |
| June | $488.02 |
| July | $542.69 |
| August | $541.80 |
| September | $701.13 |
| October | $454.39 (We bailed mid-month) |
And before you ask, yes, this ate into our profits a good amount. Remember, this was all back before the beautiful dashboard you see today existed!
Hopping back to the re-development of V1 (just for a moment), one of the largest challenges was also migrating the data. I wrote a script to process it all automatically but we had a few killer whales that had an incredible amount of data. One of our customers has a site with user-generated pages, all tracked by Fathom. Bearing in mind that we store a row, by the hour, for each page, you can imagine how much data there was to move. So moving customers like that was the biggest challenge of the entire migration. It wasn’t just an export/import job, we had additional processing that we did since we were merging all dashboards into a single database, and I wanted to have the hostnames/path names reused between sites. So if 100 sites all had an “/about” page, they would use a foreign key to reference it rather than creating “/about” multiple times. But once the migration was done, it was smooth(ish) sailing.
Once V1 was out the door, I was excited to return to a calm sea of work. That lasted about a few months, then we started getting serious about how we could build something so much better. I was longing for a single application set-up (I hated how we had the billing, api, collector and dashboard all separate) and Paul was dying to redo the marketing website and build a fresh UI for the dashboard to make it a much better Google Analytics alternative.
V2 - First design attempt for the Fathom Analytics dashboard
As we went through the initial design of V2, we really became aware of the art of refinement. We questioned everything. We focused on making a simple website analytics tool. This is where we started out.
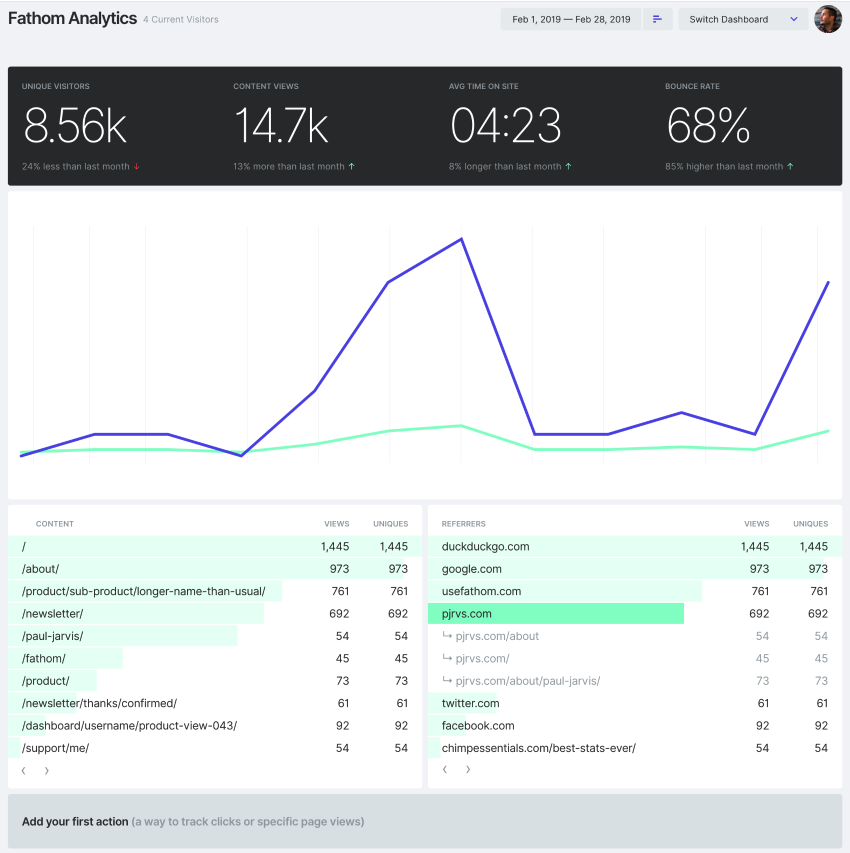
It’s a pretty solid first draft, but it’s nothing compared to how it ended up.
During the development of V2, we questioned everything. We want simple, fast software, and refuse to clutter it with features. One of the big questions we asked was “What is the use case for multiple users?”. The reason we questioned this was because we had to consider scenarios such as “What if a user already has their own dashboard when they’re added” and then we came into problems such as managing subscriptions, whose dashboard new sites went to, restricting access to certain sites, user managers etc. and it complicated the experience. So we completely killed off the idea of multiple users and opted to focus on the typical use case we see “I want to share my client’s site data with them” or “I want to share the dashboard with my business partner”. So we brought in private, password protected sharing, in addition to public sharing.
V2 - Final design of the Fathom Analytics dashboard
Once Paul had finished the final iteration of the dashboard, it was looking pretty solid!
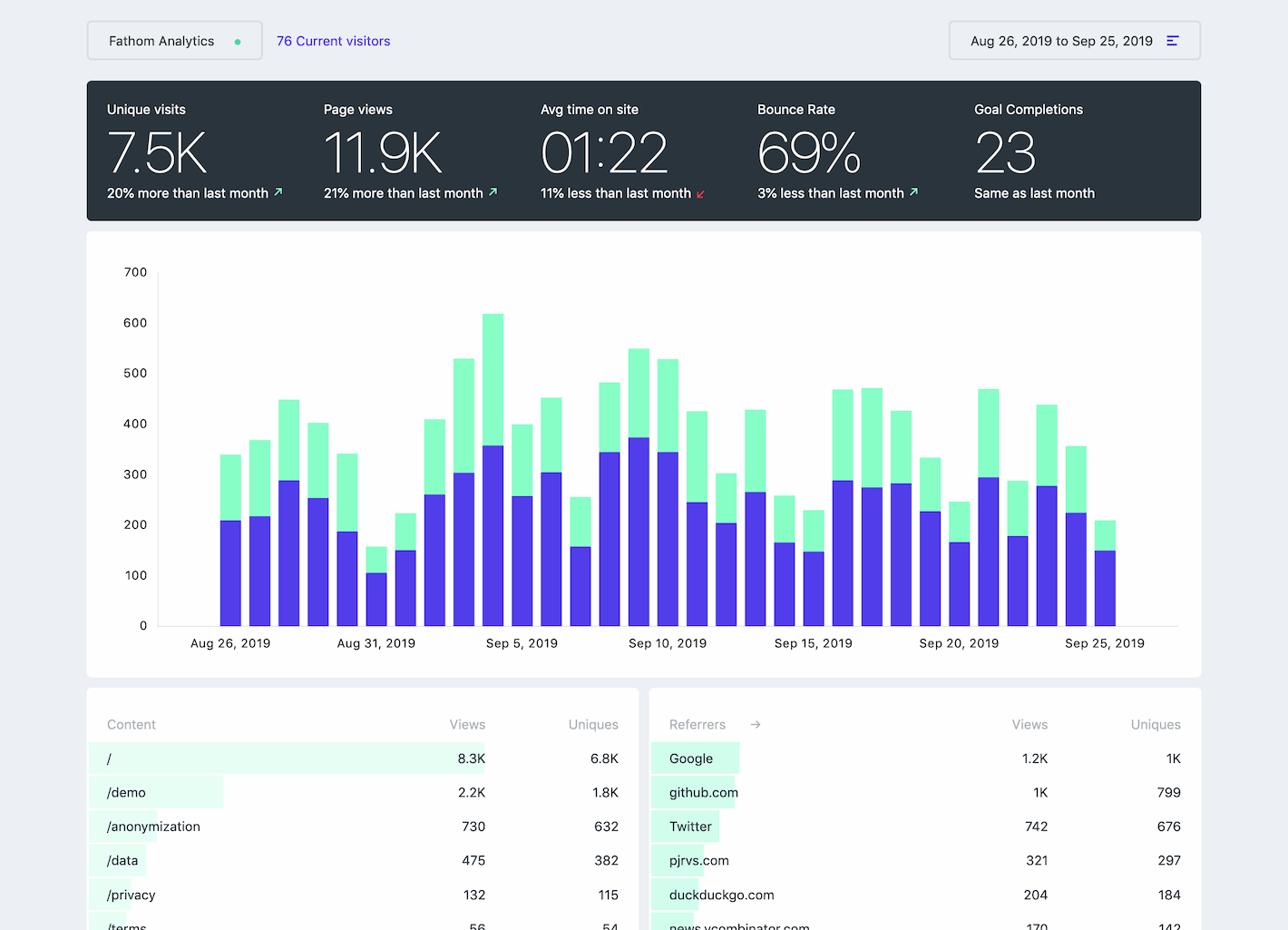
It was now time to start coding everything from scratch. We were going to write more tests than we had before and make everything so much faster. So it was over to me to start building things into a fresh EmberJS and Laravel application.
One of the first things us developers deal with when putting together an app like this is “How are we going to handle authentication?”. In V1, I used ember-simple-auth and used Laravel Passport for access keys, stored in local storage. This approach was fine but there were numerous limitations. The limitations we faced:
- When EmberJS loaded, there was a slight delay where the app could not render because we had to wait for the initial user information to be fetched (via ajax) from the server. The actual response time was fast but network latency varied.
- We had our entire frontend code exposed. This wasn’t actually a big deal, and our public dashboards do this now anyway, but I come from a background of working on highly sensitive applications where publicly exposing the frontend code would be an unwise move.
With those limitations in mind, I opted for my preferred method, which I have spoken about before, that requires keeping the frontend in the Laravel codebase. Then I modify the .ember-cli file so it looks something like this:
{
"disableAnalytics": false,
"output-path": "../public/app",
"liveReload": false
}When our CI platform (We love ChipperCI) runs deployment, it runs ember build and all the static assets compile into the /public/app folder. We then serve the index.html file via Laravel using something similar to the following:
{!! str_replace(
[
'/app/assets/vendor.css',
'/app/assets/frontend.css',
'/app/assets/vendor.js',
'/app/assets/frontend.js'
],
[
asset('/app/assets/vendor.css'),
asset('/app/assets/frontend.css'),
asset('/app/assets/vendor.js'),
asset('/app/assets/frontend.js')
],
str_replace('[[window_variables]]', '
window.data = ' . $data . ';
window.xsrf_token = "' . csrf_token() . '";
window.stripe_key = "' . $stripeKey . '";
', file_get_contents(config('app.env') == 'local' ? 'app/index.html' : resource_path('app/index.html') ))) !!}There are a few things going on here:
- We replace paths that EmberJS adds and drop in replacements that use the asset() helper. Why? Because Laravel Vapor automatically moves our public, static assets to Cloudfront
- The next thing we do is replace [[window_variables]]. This is a line that I have wrapped in tags inside the index.html of EmberJS. This offers us unlimited flexibility to inject data from the server into window variables on first load, which then means we can instantly push the data payload into the Ember data store
- We then perform a file_get_contents to load the index.html file in. This code definitely needs a refactor. I’d hazard a guess that storing app/index.html in Redis would speed things up tremendously too. I’d need to measure latency. But I digress.
By doing things this way, it meant that we could preload data on the initial request rather than sending off an additional ajax request on load. This has lead to an incredibly fast initial load experience for the user. Overall, there are pros and cons to each of these, but I’m a huge fan of this way.
In V1, the way we built page view aggregation was:
- Queue up each pageview in the pageviews table
- Run a cron job every 15-30 minutes
- Lock the rows we are processing (not row-level locking but update a boolean column)
- Load those same views into memory (where locked = true)
- Extract distinct hostnames and schedule them to be inserted or ignored
- Extract distinct pathnames and schedule them to be inserted or ignored
- Aggregate the page view at site level, page level and referrer level
We then had a Laravel queue worker (separate Heroku Dyno) that prioritized hostname & pathname processing ahead of page views, because we required them to be inserted to avoid duplicate entry. Yes, reader, I hadn’t thought about insertOrIgnore at the time.
Moving forward to V2, we opted for a transaction-based approach. This seemed great, having all queries chucked into a single transaction, making sure we didn’t duplicate anything during aggregation. We later came to learn that we were in for a world of pain when it came to deadlocks. One of the reasons I did this in the first place was because I had thought this would reduce the I/O of RDS Aurora. More on that later.
Deploying V2
All the infrastructure was planned out. We were going to stay with Heroku, improve efficiency and start working to reduce our excessive bill. We were slightly worried about our database options as we grew, since their options were limited, but we would deal with those issues when we got to them.
But then something happened at Laracon…
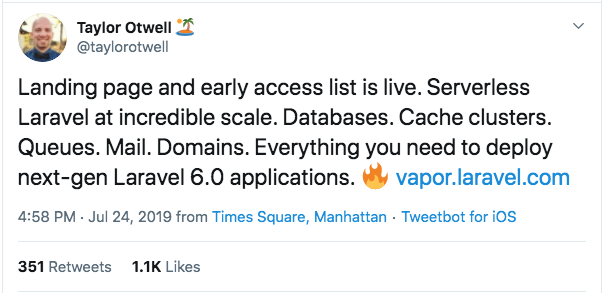
This was a complete game changer for us.
- Automatic scaling on the HTTP level? Check.
- Infinitely scaling queues? Check.
- Easy deployment with rollbacks? Check.
- Easy database deployment? Check.
- Multiple environments? Check.
- Incredible price for the interface managing AWS? Check.
- And so much more.
We were caught completely off guard with this but we were immediately excited about what this meant for Fathom. So we immediately signed up and then, as soon as Taylor announced BETA, we asked him for early access. We got set-up that day and I was beyond excited.
And before you say it, I know what you’re thinking: “Yes, Jack, we know about Vapor / Serverless / FaaS but how much is this going to cost?”. And that’s an important question. We spent a heck of a lot of time predicting prices, but it’s very hard to do.
How the heck do we estimate cost?
For us, we have a few areas that we should estimate cost on (e.g. the ajax pings for live visitors) but we focused mostly on the page view collection. Sure, there will be exceptions here, where someone leaves 3 tabs open with Fathom loaded, pinging the server every 10 seconds, running 24/7 for a month, but we’re ignoring those edge cases.
The way we attempted to price things out was by page view. We also used the following guidelines
- Do not factor in AWS Free Tier as it’s limited and doesn’t scale
- Always overestimate (aka build contingency into estimates)
- Always assume the customer will max out their allocated capacity. In our case, we limit customers by page views, so all our calculations assume that customers will max their page views out.
With that in mind, we started to attempt to price things out:
- Lambda Request
- $0.0000002 per request
- $0.000003334 for 200ms of 1024MB
- Cloudfront (Tracker file)
- $0.00000204 for 16KB Region Data Transfer Out to Internet = ($0.1275 per GB) / 1000000 = $0.0000001275 per KB. Our tracker file is 16KB (ish), so we multiply that by 16
- $0.0000011 per HTTPS request
- Simple Queue Service (we still aren’t sure exactly how this works in terms of pricing, as polling costs too)
- $0.0000004 initial queue up
- $0.0000004 to retrieve it
- $0.0000004 processing time
- $0.0000004 to mark it as done?
- Lambda Aggregation of Page View
- $0.0000002 per request
- $0.000003334 for 200ms of 1024MB
So by this point we’re at $0.000011808 per view. But we haven’t factored in the RDS (database), Cache (ElastiCache), File Storage (S3), NAT Gateway, DNS (Route53), Load Balancing (Elastic Load Balancer), Basic Logs (Cloudwatch), Key Management Service and everything else.
The Database (RDS)
For the database, you want to run something with high availability (we provisioned it with Laravel Vapor and then added high availability in the Vapor interface). We’re currently running RDS for mySQL, using db.t3.large. That costs around $200 / month and then there are other storage costs. We originally tried to use Serverless but it just wasn’t scaling fast enough for my liking. We managed to crash it a few times when performing our data migration, so that turned me off. It was also a pain in the ass to try and calculate the costs of Aurora because they price “per ACU Hour”, which is fine, but then they have this “I/O Rate” pricing which, after Googling many times, I still don’t understand. Does this mean that we should be anticipating 1 x I/O per query? And before you cheeky DBAs chime in, I will admit that this misunderstanding is down to my lack of experience with RDS.
So we ended up going with an overprovisioned, fixed-size database. We’re comfortable with this because, in the worst case scenario (we suddenly get a huge inflow of traffic), we receive a notification that our database is under load, we have a few things in place:
- Our queue worker concurrency is limited (thanks Vapor).
- The queued jobs check for the database connection each time they run. If the database were to go offline (due to load), the queued up page views would be deferred and released back to the queue for 3 minutes. This means we’d have time to manually scale up RDS and not lose any page views.
So we’re paying a good amount for the database and we’re happy. But you can see how it’s challenging to tie the RDS costs to “per pageview”.
The Cache (ElastiCache)
Back in V1, we used Heroku and we paid $15 for 50MB of Redis, which we always felt was a bit of a rip-off. When we moved to Vapor, we deployed a cache instance through their interface and we now pay $13 for nearly 600MB of Redis. Considering that we paid for multiple Redis instances before, this is insanely great value for us. All our sessions utilize Redis (separate Redis DB) and we cache a fair bit. Over the last 30 days, we’ve had 90,086,673 cache hits and an average Average CPU Utilization of 2%. That’s pretty remarkable considering the cost, and it saves a ton of load on the database. Additionally, whenever we need to replace our cache with something heavier, we just need to provision a cache cluster and modify our vapor.yml file to attach it. The simplicity is remarkable. We’ve only scratched the surface with caching and are looking forward to doing more in the future!
DNS
Vapor makes it easy to manage DNS. It takes a few clicks to provision wildcard certificate for your domain and link it to any environment you wish.
With regards to Route53 costs (DNS), we haven’t factored this into the cost either. Even hit of cdn.usefathom.com is a DNS lookup etc. and it’s very challenging to price when you factor in things such as DNS cache.
SQS
This is the piece that excited us the most when Vapor was launched, because we’ve gone from having the concern of “What if we exceed the Redis size limit for our queue” to “What if SQS runs too many concurrent queue workers and wants to process jobs too quickly?!”. What a hilarious problem to have. Fortunately, there is a configuration option in Vapor that lets you limit the concurrency of queue!
You need more pricing information, damn us!
I get it. We wanted to know the exact cost per page view ahead of time. Myself and Paul spent many hours on Skype attempting to calculate our cost, because we have other expenses, and then we need to build in room for eventual salaries & profit. Unfortunately, it’s near impossible to get an exact figure, so you need to be comfortable with an estimate.
When we ran things on a handful of VPS’, we received DevOps quotes of $1,000+ a month. So without Vapor & Lambda, we’d be looking at the cost of the infrastructure AND the cost of someone to monitor our servers full time. Because neither of us are willing to take on this kind of responsibility. I don’t want to receive a call at 3AM telling me our entire fleet of servers is offline.
So when you consider the cost of DevOps, the cost of Vapor & AWS become negligible. Our fully managed FaaS / managed services cost us less than the salary of a full time DevOps human. At the end of the day, your infrastructure is powering your software. As long as you’re still making sufficient profit, it’s not a stress. So we sleep well knowing that we’re paying a premium to have people smarter than us to keep our infrastructure online.
Do we have any tips for using Vapor/Lambda?
Oh you bet we do. I’ve sent the Vapor support team over 50 emails! I’ve been trying to do some pretty “out there” things on the platform and they’ve been nothing but helpful.
I’m going to wrap up this article by listing some Vapor tips that will help you:
- Experiment with different sizes of Lambda runtime. We started off using 1024MB for every request (including page view collection), which was expensive. We reduced it to around 302MB recently and it’s only slightly slower but it’s significantly less expensive.
- If one part of your application needs less memory, and another part needs more, consider breaking the application up into separate environments. The beauty of vapor is that you can easily share the database, cache etc. between environments by updating vapor.yml. For Fathom, we have the main ‘fathom-production’ application for our dashboard and then we have ‘fathom-collector’, which handles hundreds of millions of page views each month, at a slightly lower memory allocation. You just need to remember to deploy both during your CI build.
- If you are wanting to limit your CLI concurrency, don’t go too low! When doing our data migration, so many workers spun up and it was like our database was being DDoS’d. So we reduced our cli-concurrency to something low like 5. The logic being that we wanted to perform the migration slowly. But doing this caused us some additional issues. Vapor actually uses this concurrency to deploy it’s “on-demand” commands. So by limiting the concurrency, we weren’t able to run commands from the Vapor interface since they were all in use.
- Vapor creates a load of buckets in S3. They only keep about 20 deployments worth, making it easy to rollback as needed.
- I don’t understand why anyone would use AWS API Gateway with Vapor. This is potentially naivety on my part but Taylor highlights the huge discounts that ELB brings. In the Vapor documentation, it states the if an application receives about 1 billion requests per month, using an Application Load Balancer will save about $4,000 on the application’s monthly Amazon bill.
- You can add multiple databases to an environment, you just can’t add them all in the environment file. To add a secondary databases, you need to add in the environment variables yourself. The same applies to cache clusters
- When returning images / PDF files etc. make sure you add the X-Vapor-Base64-Encode header else Vapor will give you an error of “Fatal error: Uncaught Exception: Error encoding runtime JSON response: Malformed UTF-8 characters”. Yes, they document it, but some of us miss pieces in the documentation, you see.
- At present, there is no way to prioritize certain queues with SQS. That would be pretty cool but I can see it being technically challenging to build.
- Laravel has an API that you can easily use. It’s not documented yet but you can work it out by reading this. I also used DevTools in Brave to look at the ajax requests the Vapor UI fires since it uses the same API.
- If you have any long-running requests, make sure you remember to increase the timeout of Vapor web requests.
- If your queued job is going to take a few minutes, make sure you adjust the Queue Visibility timeout, otherwise the job will be retried whilst it’s still executing.
- Don’t forget that you can use Redis for both Cache and Sessions.
php artisan cache:clearcan still be run without removing sessions. Paul Underwood wrote a good article on this. We went live with our sessions stored in the database. Upon switching them to Redis, we saw incredible speed increases. - If you don’t want to use SES with Vapor, you can add
mail: falseto your environment config invapor.yml. - Laravel Vapor does not support Lambda@Edge at the moment but it’s on their list. No ETA yet.
Anyway, we are very happy with our move. We started off with a handful of VPS’, enjoyed wonderful service from Heroku but are now happy that we’ve settled with Vapor / AWS.
Summing it up
The reality is that it’s absolutely easy to create and sell a new simple analytics software tool, but it’s not easy to do it well. Building a privacy-focused analytics platform is not a side project. It’s a challenging task and you owe it to your customers to invest in the very best infrastructure. After all, they’re paying you to collect anonymized data for them, and they expect decent uptime. If you’re running your analytics platform off of a single VPS, and your hardware goes up in flames, then who will you call? Yes, smart ass, you’ll call the fire fighters, but your stat collection will be offline and MIA.
That’s all folks. Hope you enjoyed. If you have any questions or comments, DM me on twitter @jackellis.
Looking for some Laravel Tips? Check out Jack's Laravel Tips section here.
You might also enjoy reading:

BIO
Jack Ellis, CTO
Recent blog posts
Tired of how time consuming and complex Google Analytics can be? Try Fathom Analytics: