
Making the world’s fastest analytics even faster
technical Jack Ellis · Aug 17, 2021In July 2021, we took our website analytics database to the next level, with huge speed and stability improvements across the board.
In this blog post, I’m going to tell you how I migrated close to one billion database rows with zero downtime, achieved a 30% query speed increase, and took Fathom to the next level.
It’s safe to say that Fathom is now bigger than anything I’ve worked on in my life. Actually, if you summed together every database I’ve ever worked with since I was 14, Fathom is over 50x bigger than that.
All of the challenges we’ve been dealing with over the last year have been very unique challenges. We’re past the point where we can easily find other people running into our use cases on Stack Overflow, and we’re in a space where we have to do the research ourselves. And whenever we hit one of those distinctive problems to solve I like to share what I’ve learned with all of you publicly.
What do you mean you’re migrating again?
We completely ditched MySQL and moved to SingleStore back in March 2021. It was a huge project and pushed me to my technical (and mental) limits. We took our analytics from slow, complex, bloated, rigid and unscalable to flexible, fast, and powerful. Moving to SingleStore changed our lives. So why am I here talking about data migration again?
There are five primary reasons why we had to migrate to a new SingleStore database.
Reason 1: Ditching UPDATEs
Since we started Fathom, we’ve been relying on UPDATE queries, which isn’t ideal for columnstore data (data stored on disk). If we moved to INSERT only (append-only), we could handle more pageviews with ease. I knew about the UPDATE limitation when we first migrated in March 2021, but it took a few occurrences of high CPU during viral times to push me to make the changes needed. We were using UPDATEs to modify columns such as bounce rate. And we had no other way to track that information.
In the graphic below, you can see the performance of UPDATE (top column) across a few seconds during a quiet period of time. In this image, the Total CPU for updates is at 21.46%, whilst INSERTS only sits at 6.22%. Yes, the run count is different but, when we get viral times, the UPDATEs CPU goes higher whilst the INSERTs stay stable.
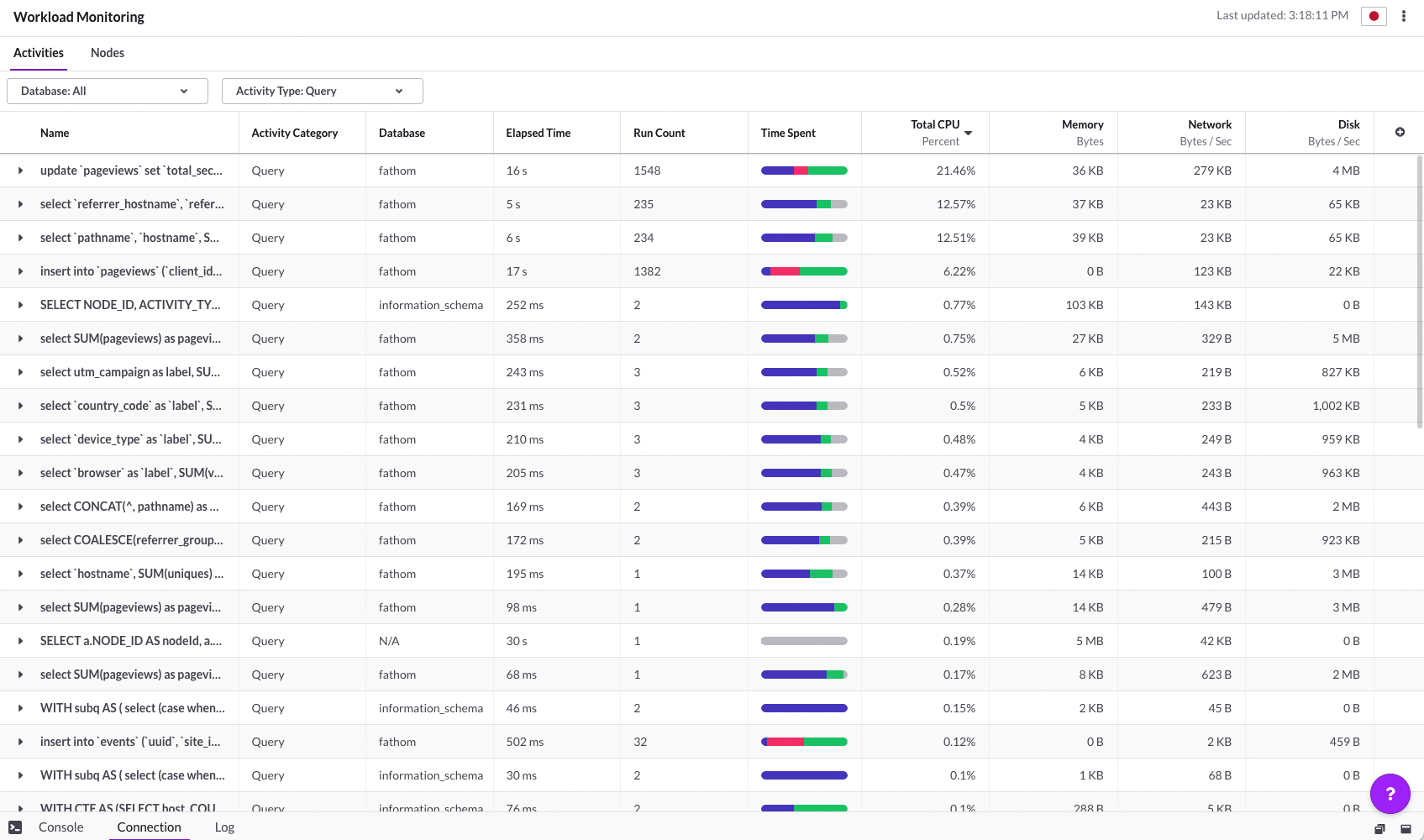
The technical reason for this is something to do with the way columnstore data is stored on disk. The reason that UPDATEs are slower with columnstore is because the row has to be marked as deleted, and then an INSERT (with the updated data) is performed to replace it. Plus the additional CPU/disk usage required. The UPDATE performance could be improved but, ultimately, they’re never going to be as fast as inserts. And something that I recently learned is that SingleStore actually inserts into memory before it hits columnstore, making insert performance absolutely incredible.
And unlike Rowstore (in-memory), the columnstore row data isn’t all stored together. Long story short, SingleStore does this because it means they can save processing power by only selecting the columns you ask for in queries. This is great for doing aggregations like SUM(pageviews) and SUM(visits), but not so great for updating multiple columns.
So we knew that we needed to change columns such as bounce_rate to be signed, not unsigned, to allow us to actually insert negative values. This would then allow us to assume a bounce on the first pageview, and then “undo” the bounce on the 2nd pageview. The way this all works is really cool, and we’re only able to do it at scale because of the database technology we’ve chosen.
Reason 2: Data skew
We had data skew in our database because we sharded by “site_id, timestamp”. This meant that if we had one customer receiving 100 pageviews in a single hour, and another customer receiving 10,000,000 pageviews in that same hour, it wouldn’t be balanced. Data skew is bad because you end up with certain partitions of your database working harder whilst others are sitting back and relaxing. You want to have the most efficient use of system resources, and since we’re not doing any kind of GROUP/JOINS on shardable fields, we don’t need to accept data skew.
And in addition to this data skew, I was having a conversation with an engineer who works at SingleStore (ex-Facebook, and is only known to me as the “wine fridge in his home office” guy) about testing out a new tool they’re working on, and he pointed out that my queries weren’t even utilizing our shard key…
Wait, what???
Well, it turned out that because our queries weren’t doing exact matches on our existing shard key (we use WHERE BETWEEN for timestamp), the shard keys weren’t really helping queries run faster, as they would match multiple partitions when running queries. So the shard key wasn’t even doing anything. I asked him why our queries were running so fast if that’s the case? His response was that our queries were fast because Singlestore’s tech is just fast. Touché.
Reason 3: Shard/vCPU mismatch
Our shard count was off. When using SingleStore, the advice is to use one shard per CPU core. We had 16 vCPU cores and only eight shards. This meant that parallelism would only execute at 8x maximum. There’s a whole bunch of deep query optimization to think about in this area (latency vs throughput), but it’s beyond the scope of this article. The TL;DR is that extra cores help with concurrency but not with individual query performance. So we knew we needed to match up the shards to vCPU.
Reason 4: Dashboard speed improvements
We wanted more speed (via parallelism). If you’re using a single shard to store data for a site, you will only have a single shard running all of the aggregations when running queries on that site. Why would we want this? It makes much more sense to have our whole cluster working hard. Even with network latency, we still have sixteen vCPUs working hard instead of one.
- If we shard on
site_id, that means all pageviews for a site will be stored on a single shard, which is backed by 1 vCPU. This will be super fast for small customers but very slow for customers with hundreds of millions of pageviews, where more processing is needed. - If we shard randomly, that means pageviews are distributed between 16 shards (backed by 16 vCPUs). So when a big customer loads their dashboard, they’d have 16 vCPUs working on their query. Yes, we have additional network latency to think about, and the aggregator will have to wait for each shard to complete it’s workload before it can return results to the client, but the theory is that we can work on larger amounts of data more efficiently. We always want to plan for the long term.
When considering these trade-offs, we were confident that keyless sharding was going to lead to faster dashboard reports.
Reason 5: Increased insert throughput
We wanted increased throughput, meaning that we wanted to handle even more incoming pageviews/events per second without increasing our cost. Our queries were already fast across the board, but we concluded that we’d be okay with an extra few milliseconds on the dashboard (SELECT queries) if it meant that we could scale even higher on the INSERT part.
Because we had a shard key set on our database since March 2021, this meant that during inserts the aggregators had to figure out where they were going to store the pageview data. And since we don’t utilize shard keys in our reporting, why should we want this extra computation? Moving to random sharding will mean an increase in throughput, which leads to lower total cost of ownership.
Planning the move
As you know, migrating close to one billion database rows with zero downtime isn’t the easiest thing in the world. And even though I’ve migrated the Fathom database five times, no migration is ever the same. With every single migration comes a blank planning document, with baseline feelings of overwhelm and anxiety. The difference between my first migration and this migration is that I now understand that the feelings are normal. Those feelings don’t mean you can’t do it. Those feelings mean you’re stepping out of your comfort zone and, with determination and focus, you will turn that blank canvas into a beautiful painting.
Database design modifications
Before we got into the details of the migration, we had to get an idea of the database changes we wanted to make. We wanted to move from UPDATEs to INSERT only, which meant we needed a way to default to a value (e.g. is_bounce=1) and then have a way to “undo” that value when we receive a second pageview (meaning the first pageview was not a bounce). So here are the database changes we made:
- For any fields that we updated (bounce, known_durations, duration, etc.), we converted them to a SIGNED field. This would allow us to default to a +1 and then insert a -1 to undo it if required. This worked great for us because we never return single pageview rows to users as everything is always summed up & grouped.
- We had a few fields that were using BIGINT that could easily be converted to smaller fields. I used MAX() to establish which fields I could shrink down.
- We were able to drop the user_signature field. This is just a SHA256 hash made up of IP, User Agent, Site ID and a cycled salt. We previously needed this to perform updates for obvious reasons, but now we can nuke it. This was a win for us because it means that the pageviews table no longer has any kind of anonymous identifier stored beside pageview data.
- We completely dropped our shard key (site_id, timestamp) and moved to completely keyless sharding.
- We kept the sort key the same (Site ID and Timestamp).
All things considered, the schema modification was pretty small but would bring some incredible improvements.
As part of this database move, I spoke with Carl Sverre, who works at SingleStore and is one of the nicest guys I’ve ever met. He follows me on Twitter and knew that we were doing a big migration, and wanted to make sure we were successful. He taught me an absolute ton, and I’m incredibly grateful. The funny thing about talking to Carl is that all of this database stuff is completely normal to him. But to me, it’s magic. And, it’s improving Fathom as a service and helping us live better lives. I’m really not joking here. Knowledge is power. And whilst I’ve never wanted to be a DBA (Database Administrator), I’ve realized that I don’t have a choice in the matter.
Testing the water
Before diving headfirst into this migration, we needed to test things.. We weren’t going to test every query we have, but we would test our more complex queries. In theory, we were solid on what we wanted to do, but we all know that the proof is in the pudding, so we headed to the kitchen.
Test 1 - Keyless sharding with existing sort key
We got straight into testing out our ideal solution. This database would have no shard key for rapid ingest and maximal parallelism of resources but would keep the “sort key” to allow the SingleStore engine to eliminate segments of data that weren’t in our designated site/timestamp when reporting on the dashboard.
I had spoken to Carl the day before about how to migrate data, and he recommended that I use INSERT INTO new_database SELECT * FROM old_database. Now I wouldn’t dream of doing this in MySQL, as it would probably fall over and kick my dog, but I trusted Carl’s advice.
So I ran the query, our data nodes’ CPU usage shot up to 100%, and I shat my pants.
But we were good! What appeared to be happening was that the data nodes would utilize as much CPU as possible and then make way for any queries that came through from our dashboard. I don’t know if that’s what was happening, but that’s what appeared to be happening because we saw zero slow-down on data ingestion or on our dashboard.
I ran this data migration on a Saturday, and it took 55 minutes and 11 seconds. Yes, I know, isn’t that ridiculous? I expected it to take 7-12 hours. After the migration, the queries I decided to test were the SUM() and GROUP BY pathname, because those are the ones that were historically problematic. We compared Fathom (our own site, with a few million pageviews) with the biggest customer site we have using Fathom:
Fathom:
- Old database: 66ms average
- New database: 70ms average*
Fathom’s biggest customer:
- Old database: 2,265ms average
- New database: 1,687ms average
So what we were seeing was that we had a 4ms performance decrease on a small site but saved 578ms on larger sites. My gut tells me this was related to network latency of new (scanning ALL shards) vs old (scanning SOME shards), but I’m not 100% sure. This trade-off was an obvious win for us, as being able to scale with growing data sets is a huge priority for us. So far, so good.
It’s important to note that this comparison wasn’t completely fair, as I hadn’t fully optimized the new database. This meant that we were comparing an optimized, old database to an unoptimized, new database. Regardless, the numbers had still improved, but we wouldn’t have seen that 4ms slow down on Fathom, and Fathom’s biggest customer query would’ve been faster on the new database.
Test 2 - Sharding by Site ID and sorting by timestamp
I wanted to test this option because I wondered if isolating to a single shard (meaning less network latency, and having a single machine do the calculations) would be faster.
This migration took 2 hours and 10 minutes to run, which really shows you the difference between option 1 (keyless sharding) and this option, where it has to figure out which shard to chuck it on. This alone had already put me off sharding, before I’d even run the query.
I ran a query for our biggest customer and it took eight seconds. I attempted to run it three more times and it still took eight seconds. That’s over six seconds slower than our previous test. This wasn’t going to work, but I was happy that I had tried this experiment. We clearly needed more computing power for this stuff.
Test 3 - Increasing the partition count
SingleStore recommends one partition (shard) per CPU core. We have 16 cores, so it defaults to 16 partitions. For my final test, I tried 32 partitions... but there was no difference, so I stuck with 16 partitions.
Migration day
Well now, isn’t this deja vu. This time, the biggest difference is that the plan and migration all happened within a few weeks, whereas our previous migration took months of planning. Admittedly, this migration was much simpler than our previous migration, but I’m also much more experienced now. This migration could’ve been pushed a few more days but, to be completely transparent, I found out my daughter was staying the night at her grandparents, so I quickly reminded myself about Parkinson’s Law.
Here’s what my plan for the day looked like. It’s “as is” with a few edits for clarity. My objective here is to give you an insight into what I was thinking about and how I plan big migrations.
Between 7AM and 4 PM
- Figure out how we’re going to modify the Current Visitors script
- Check that COUNT() is not used in any of our aggregation queries, as we will now have 1-2 rows per pageview, and a cheeky COUNT() would ruin everything
- Write new code to deprecate UPDATEs
- Modify code to look at timestamp. After hash change (midnight), start doing the
INSERTonly and targetsinglestore-newdatabase configuration - Make sure we use a different key for “Previous pageview”, since the new previous pageview won’t contain user signature etc., it will contain pathname, hostname, etc.
- Refactor: When there is a previous pageview set, INSERT a clone record of the previous one and make the following changes
- visits, sessions, uniques, pageviews are all set to 0
- Exits set to -1, since we are marking the previous pageview as “not an exit” (to Fathom customers, yes, this does mean we have data on which pages folks exited from :P)
- total_seconds set to the value we calculate between original timestamp and CURRENT_TIMESTAMP (well, now() in Laravel)
- known_durations set to 1 IF the total_seconds value is greater than 0
- bounce_rate is set to this ~ONLY IF~ the previous value is 1: -1
- Modify code to look at timestamp. After hash change (midnight), start doing the
- Write new tests
- Create new connection in Laravel called
singlestore-newin config/databases.php - Create new database called
production - Migrate all other tables that we have in rowstore (not related to analytics, but we were using SingleStore for some other tables)
- Copy events table structure (review it too)
- Copy event_properties table structure
- Bring in new pageviews structure
- Temporarily disable all cron tasks that touch site data
- Make it so events insert into new events table (on singlestore-new) after time change
- Switch production (NOT pageview collector, just dashboard) to use singlestore-new for everything that ISN’T reading from pageviews or events
- Deploy dashboard
- Pull in data for those rowstore tables we migrated
- Final code review for process pageview & process event (note to reader: I had added a time check so that the collector will automatically use singlestore-new (our new DB) after midnight UTC)
- Deploy collector
4PM
- Move events to new database and pick a >= timestamp value (to help us move newer events after move at 7PM)
INSERT INTO newdb.events SELECT * FROM olddb.events - Move pageviews to new database and pick a >= timestamp value (to help us move newer pageviews after move at 7PM):
INSERT INTO newdb.pageviews SELECT * FROM olddb.pageviews - IMPORTANT NOTE: With pageviews, it’s possible that the last 30 minutes can actually be modified. So I’d say go 1 hour back from the latest timestamp.
- Once both are complete, using the given timestamp values (aka the last record inserted into the database), do a COUNT() and various SUM()s on various columns to evaluate data integrity
7:02PM (00:02 UTC)
- Events migrated up to 2021-07-28 20:43:11. Start at >= 2021-07-28 20:43:12 when doing migration
- Pageviews migrated up to 2021-07-28 20:43:12. Start at >= 2021-07-28 20:43:13
- Check that no new pageviews are coming into old database
- Check that no events are going into old DB
- Events migrate: INSERT INTO production.events
SELECT FROM fathom.events WHERE timestamp >= '2021-07-28 20:43:12’; - Pageviews migrate: INSERT INTO production.pageviews
SELECT * FROM fathom.pageviews WHERE timestamp >= '2021-07-28 20:43:13’; - Change env in production to rename singlestore database to production
- Change env in collection to rename singlestore database to production
- Switch all
singlestore-newitems in codebase just usesinglestorein production - Test the data manually to make sure it’s coming in as expected. And run various SUM() comparisons on old data to new data (up to JUST before the DB switchover)
7:30PM (00:30 UTC)
- Re-enable pruning commands
- Re-enable wipe site feature
- Get Champagne and celebrate
The above was my plan, which I followed to a T, but I want to clarify a few things about how I do a data migration:
- Make it so there’s no way a user can wipe/delete site data temporarily, as you don’t want to migrate data that should’ve been deleted
- I migrated every single row with zero limit, but then I deleted the last 1 hour of data from the new database. I did this because data within a 30 minute window (from CURRENT_TIMESTAMP) could still be modified by our existing UPDATE queries. So if I didn’t delete that last 1 hour, we could end up with some big mismatches. I chose 1 hour instead of 30 minutes because it felt better to pad it
- Once I’d deleted the last hour of data from the new DB, I found the max(timestamp). I then checked it against the old DB to make sure I had all entries for that timestamp in the new DB. Fortunately, I did, else I’d have to do some manual copying.
- Following this manual check, I ran a COUNT() on both databases. So in my plan, you can see that the latest timestamp for pageviews was 2021-07-28 20:43:13. So I ran
SELECT COUNT(*) from pageviews WHERE timestamp <= "2021-07-28 20:43:13"on both databases. The number matched, and life was good - Then when the database switched at midnight UTC, I would just have to migrate rows where the timestamp was greater than 2021-07-28 20:43:13.
- We had the advantage that at midnight UTC our unique hashes (how we identify visitors) resets, so there was no chance of an UPDATE on data older than 00:00 UTC. If we had to deal with that, we would’ve done the same technique as above, in smaller chunks around midnight
Everything went perfectly. I was so happy that I went to bed smiling. If things had gone wrong then it was going to simply be a case of copying all entries >= 00:00:00 from the new database back to the old database, and switching the “in-use” database from the new to the old. I had a rollback plan in my head, but I was confident in my tests, as I’d written lots of them.
The morning after
I woke up feeling good, but then I checked some data. The good news is that my tests were solid, so all data ingested was perfect, but the current visitors and the bounce rate were reading incorrectly.
Current visitors
The current visitors were returning double the visitors, because it was doing something weird. I ended up solving this by using WHERE HAVING SUM() >, which rolled up the rows and brought things back to normal.
Bounce rate
There was an issue with the bounce rate, and it was displaying the completely wrong number. And after a few hours, I was starting to stress about it, as I couldn’t fix it. And surely people would soon send in support emails pointing it out. In desperation, I wrote some complex subquery nonsense, but quickly found that it wouldn’t scale. I emailed Carl to see if he could help debug the performance issues I was having, and he suggested we jump on a call. We went through it and, within 5 minutes, he had pointed out that I was approaching this incorrectly: I could use a simple IF statement in my query (for historical data) which took this Frankenstein’s monster of a query from 15 seconds to mere milliseconds. 5 minutes of Carl’s time completely saved my day, and I’m so unbelievably appreciative. Thanks Carl.
The case of the slow query
For the first few days after the move, our dashboard was really slow when you tried to filter it. I kept saying to Paul, my co-founder here at Fathom, that it was just a case of “query planning”, something that SingleStore’s engine does to optimize queries, but things just weren’t getting better.
I was reading through everything I could, and then I stumbled into an area in their docs called autostats. I ran an EXPLAIN with our slow queries and it revealed we were missing autostats. I followed the advice it gave me and added autostats to every column that it told me to, and we took our dashboard from “what is going on here then, governor?” to unbelievable speed improvements. Developers, take note of this, because this could catch you off-guard too. I’m not 100% sure how this autostats thing works (something about sampling), but it’s used to make your queries faster, and you need to enable it if you plan to do lots of custom, flexible filtering (which we do). SingleStore they told me that it should’ve been enabled by default in 7.0, so I may have caused this issue. Either way, it’s good for me to write about it for folks searching for help in the future.
How’s data skew looking?
As I said earlier on in this blog post, we needed to reduce data skew, to ensure the best possible utilization of our cluster.
Before
- Highest partition had 109,006,971
- Lowest paritition had 107,745,261
- Difference between smallest and largest partition was 1,261,710 rows
- Not a huge problem at our scale but as we attract more larger customers, this could’ve got problematic. And there’s no guarantee that the data skew wouldn’t grow to 20%+. Maybe randomness would’ve helped solve the issue? But there’s no guarantee
- As a percentage, the skew is around 1.16%
Now
- Highest partition has 54,975,873
- Lowest partition has 54,948,895
- Difference between the partitions is 26,978
- As a percentage, the skew is around 0.04%
- Since we don’t use a key for sharding, not only does that mean we get improved ingest (INSERTS), it also means we will maintain equal sharding of data indefinitely
- We doubled the shards (partitions) in the database, so don’t get hung up on the specific numbers, focus on the percentage difference. Before was 1.16% data skew, with the likelihood that it would grow with larger customers. Whereas now, we’re at 0.04% data skew, and a guarantee that we’ll continue to be balanced across our cluster
Are we there yet?
No. A week after doing this migration, I migrated our entire MySQL database to SingleStore, and cut about $1,000 - $1,500 off of our AWS bill. No more expensive NAT gateway, no more RDS for MySQL and no more provisioned storage for IOPS (which we never used and only had so that we could deal with viral events).
This whole migration was also needed for the new Fathom API as well. We wanted to support high scale on our API, and we wanted to be confident that we had the right technology behind it. Because we have sites, pageviews, events, and everything else in SingleStore, we’re ready for enterprise scale API usage. We’re already in talks with CTOs who want to use Fathom to power their applications, sending many millions of requests our way, and now we’re ready.
In addition, we completely nuked Redis and are now using SingleStore for all caching. That’s going to be a future, quite nerdy blog post. For us, we had around 100GB of free RAM available, so why pay for Redis & NAT Gateway?
What next?
Slow down, sunshine, let’s take a moment to reflect on what we’ve now got in our hands.
Previously, we had an analytics store that we would insert & update to. This was fine, but updates were inefficient and weren’t going to scale. We now have a completely append-only analytics datastore. This also means that if we ever want to restructure our database in the future (e.g. if we add in more vCPUs and want more partitions), we could do a INSERT SELECT without worrying about updates, since it’s append only. Also, we’re now in a position where the order our SQS jobs are processed in doesn’t matter. This helps us scale out on SQS as we’re not concerned about FIFO. Finally, our total cost of ownership (TCO) is going to stay low because inserts are cheap as chips, and we’re feeling good.
So, what is next for our infrastructure?
- We’re going to soon be going all-in on SingleStore. The risk there, of course, becomes single point of failure (which is especially important for pageview collection). The way we will mitigate that risk is that if SingleStore goes offline, we will queue up jobs to be processed, and utilize DynamoDB to establish the order they should be processed in. And then we can comfortably handle hundreds of millions of pageviews in our backlog, and we can recover when needed. Sure, in the rare event of a SingleStore outage, DynamoDB will be expensive, but that’s fine with us. We don’t want to drop pageviews.
- We’re hoping to take SingleStore multi-AZ soon.
- We’re currently running into some headaches with the fact we’re using Lamba & SingleStore because, as a lot of you will know, Lambda doesn’t do the kind of connection pooling we need, and we’re constantly opening & closing new connections. We ran into the same problems when we used MySQL. We will soon be moving to something called HTTP API, which SingleStore has recently built, and it means SingleStore will pool connections for us (similar to AWS RDS Proxy). We’re stoked about this because it will mean faster queries everywhere, since we don’t have to create a new connection for every single pageview (imagine that?!) I’ll be creating a new Laravel database driver for this, which will effectively be a decorator for the MySQL database driver, and it will allow us to use SingleStore with Eloquent & Query Builder. Of course, we’ll open-source it when it’s complete.
Fathom is a premium, privacy-first alternative to Google Analytics. We invest hundreds of hours on this, we spend large amounts of our revenue on reliable infrastructure and we guarantee an incredible level of service availability. But hey, this isn’t the place for a sales pitch ;)
For high-stakes migrations, you will always experience high amounts of adrenaline. Your chest will be tight, and your throat will be sore. You’ll feel it in your chest, and your head will be wired, but I’ve learned to embrace these feelings, as this is what progress feels like.
So I hope you enjoyed this detailed journey through our latest, big database migration. We’re now in an incredible place, but there’s still so much room to improve. And I’ll make sure that I keep sharing everything.
P.S. Make sure you follow me on Twitter, as I work in public (to the extreme), sharing all of our challenges & solutions in real-time.
Looking for some Laravel Tips? Check out Jack's Laravel Tips section here.
You might also enjoy reading:

BIO
Jack Ellis, CTO
Recent blog posts
Tired of how time consuming and complex Google Analytics can be? Try Fathom Analytics: