
Why we ditched DynamoDB
technical Jack Ellis · Sep 29, 2021I can’t believe I’ve written this article but, after being very publicly excited about DynamoDB for over a year and building up a huge mailing list around our plans to put our entire database into DynamoDB, we’ve now completely ditched it.
DynamoDB started off as a technology that would change our world, but it ended up being a massive roadblock to us being able to price competitively at scale for our web analytics.
In this post, I will talk through how we arrived at DynamoDB’s doorstep and why we then burned the whole house to the ground.
It was all a dream
As a lot of you know, I’m a huge proponent of serverless technology. I’ve been open about how I don’t want to manage servers, monitor load or capacity plan. I want to press a button, turn it on and have it run automagically. We’re a small team, we don’t have time to manage servers, and we have a restraining order against EC2 (yes, fellow nerd, I’m aware that EC2 powers Lambda).
DynamoDB got me excited because the promise was as follows:
- Infinite scale (no CPU, memory or disk planning)
- Pay for what you use
- Highly available
- Automatic backups
And all of those values are very important to us.
We also had scaling challenges in the early days, when we were new to dealing with large scale. We believed that moving to DynamoDB would solve all of our problems, so we started planning for it.
- Infinite ingest? Check.
- No concerns about scaling? Check.
- Pay for what we use? Check.
We were ready to rumble.
Stumbling upon greatness
Now that we were keen to work with DynamoDB, we needed to query the data flexibly. How could we ingest all of our pageviews directly into DynamoDB, and then query them in any way we wished?
I’ve spoken at length about this before in my building the world’s fastest analytics article, where I tried to use DynamoDB with Rockset. The hope was that DynamoDB would ingest all of the pageview data, then we’d be able to query it with Rockset casually. They ended up being too slow and too expensive, plus there would have been a delay between DynamoDB and Rockset, which we didn’t want.
Since having minor, traumatic experiences with scale, I’ve always been nervous about using fixed-sized services. But when I found SingleStore, I discovered that they could handle such ridiculous amounts of throughput that I really wasn’t concerned. It wasn’t expensive for us to over-provision, and they didn’t flinch at the idea of us throwing tens of thousands of requests per second while spending less than $3,000/month.
Conquering unscalable infrastructure design
Until September 2021, we had our infrastructure set up in a way that wouldn’t scale in the long term. For every request (API request, pageview, event etc.) that came in, we invoked a Lambda function that would open a new database connection, execute a query and then close the database connection. This works great at low scale and is how I’ve always built applications, but this isn’t how it’s done at scale. Because of this, we had significant CPU overhead on our SingleStore cluster, which I hadn’t realized until their team told us.

SingleStore has recently built an incredible HTTP API, which takes care of connection pooling and leading to substantial speed improvements, but we didn’t have the time to perform a refactor. So instead of moving to the HTTP API, we took a different path.
The problems we were facing were caused by two areas of our application:
- The Fathom dashboard (private API, jobs, etc.)
- The Fathom collector queue (the queue runs in the background and processes incoming pageviews)
With this in mind, we decided to keep the main Fathom ingest point on Laravel Vapor (the ingest point writes to SQS, our queue system), and move everything else to Heroku.
UPDATE: Less than 24 hours after this article was published, the Laravel Vapor team deployed a change to allow persistent connections within the queue. I didn't think this was possible. We have now actually moved our queue back to Laravel Vapor.
As you might imagine, the move took some work, but it meant that we’d be able to start using persistent database connections. To be clear for the non-tech folks following (let me know if you folks exist via Twitter), persistent connections meant we were able to completely remove the consistent open database connection & close database connection for every single request.
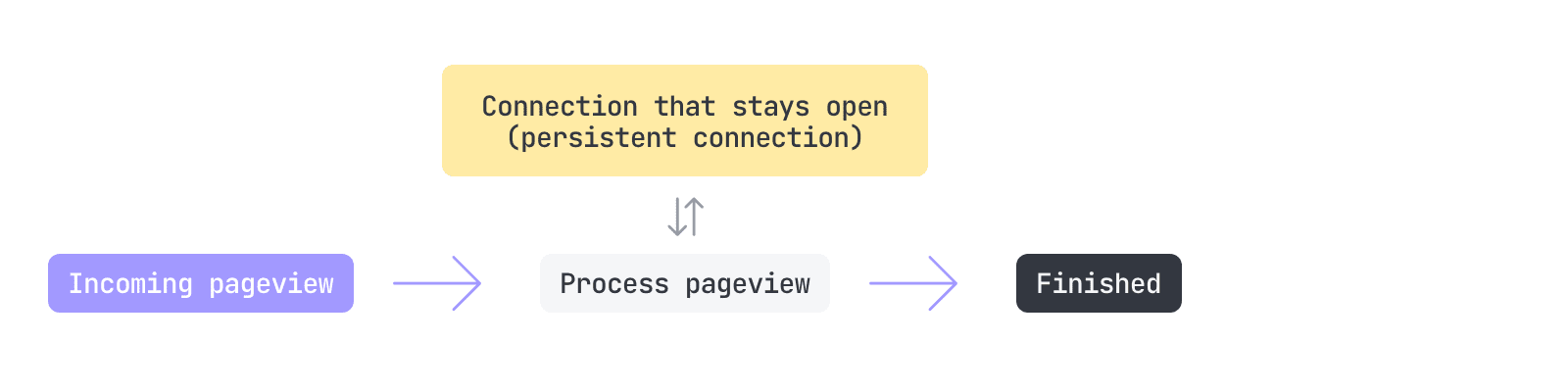
Well, this made a gigantic difference, reducing our CPU overhead by an unbelievable amount (60-80%). This meant that we were finally in a position where we were using SingleStore in the way it was intended. My dopamine ran high for around five days after this migration was complete, and I’m so happy we spent the time on this. Fathom is now better and even more scaleable because of it.
SingleStore now handles everything via persistent connections. We can perform tens of thousands (probably more at times) of inserts per second, along with utilizing it for all key/value lookups (which we previously used DynamoDB for). It handles all of our application rate-limiting and supports our unique tracking methodology—what a time to be alive.
$3,000 in savings
As we grew, DynamoDB costs were rising fast. Margins on the lower plans were acceptable, and we had room for the excessive DynamoDB expense, but it wasn’t going to work for us long term if we kept landing bigger customers.
For many months, we kept coming back to the fact that we couldn’t make DynamoDB work. If we kept prices the same and kept landing these large customers, we would end up with an unsustainable business. But if we jacked prices up on those larger plans, we wouldn’t be competitive on price. And sure, we would still land some of the larger enterprises, the cost wouldn’t be a problem for them, but we serve high traffic SMBs too, who don’t have $1 million to spend on SaaS subscriptions. It was a hard thing to balance.
We came close to raising prices, but something didn’t feel right. We knew we could do better. That’s when we arrived at the idea of using SingleStore instead. That was a fixed monthly expense, and they could handle ridiculous throughput with ease.
When we moved to SingleStore, our DynamoDB cost dropped to around $0.02 a day, and our SingleStore bill didn’t increase. This is how our SingleStore cluster operates most of the day. We absolutely expect to have to increase our bill at some point, but we’re very stable for now.
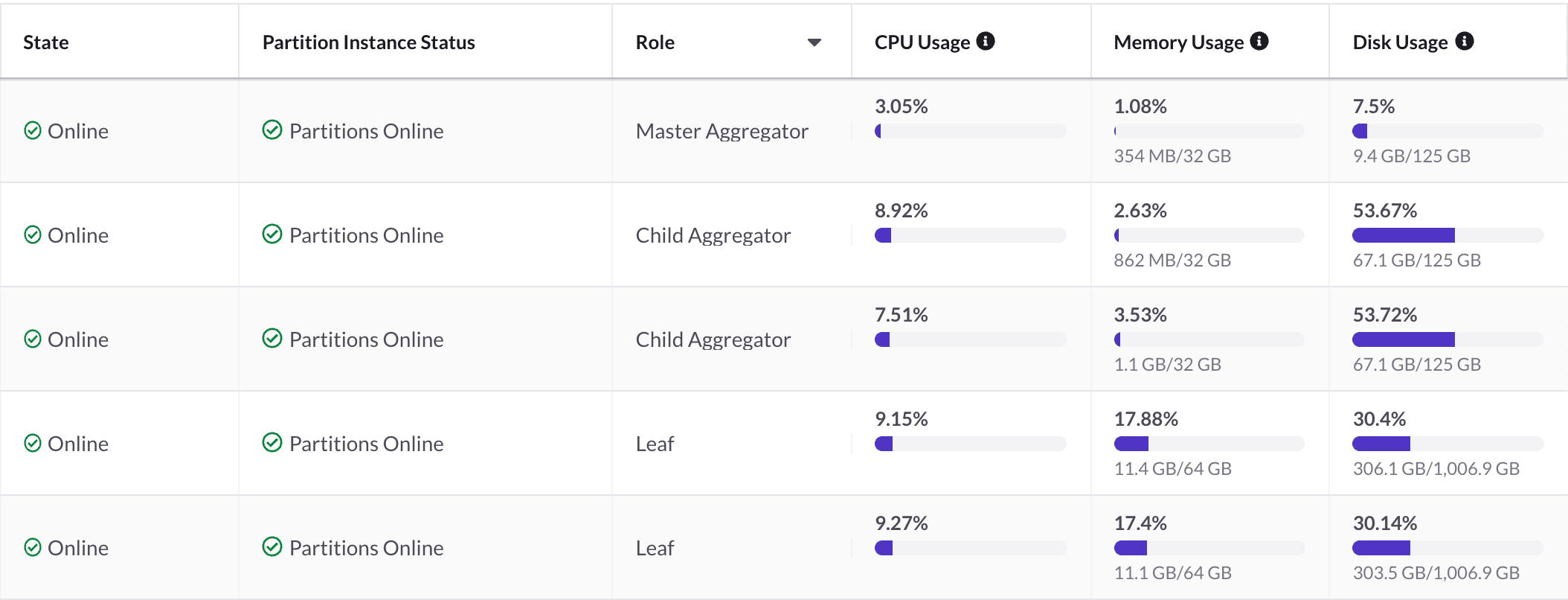
And then what happens if we get such a huge whack of traffic, and SingleStore truly can’t handle the throughput? In that rare event, we are safe with SQS (Simple Queue Service), which is infinitely scalable and holds all of our pageviews. So our worst case is that we accumulate a temporary backlog of pageviews that require processing.
The future
So we’re now in a position where we have a single database for our entire application. Highly available, moderately over-provisioned, and great value. What excites me the most is that any time we have to spend more on SingleStore and add CPUs and RAM, our dashboards will perform faster. We’ve put ourselves in a great position here. Many developers will be reading this and managing Redis, DynamoDB, MySQL and whatever else they’ve got in their stack. It’s stressful to manage all of that individually.
Our database solution isn’t serverless, but everything is built in a way that we can handle blowing past our capacity, which, as you can see, would require an additional 90%+ CPU usage and a whole bunch of extra memory usage. So we’re good. And now, the dopamine attacks have subsided, and this is our new normal, but I’ll never forget what life was like before we made this change.
We're growing at a rapid rate, as more folks are deciding to ditch Google Analytics and use a Google Analytics alternative like Fathom, so we're going to continue scaling out our database infrastructure and likely make additional changes in the near future.
A huge part of running a software business is reaching this inevitable fork in the road: you can choose to raise prices when faced with increased costs or optimize your infrastructure spend for better margins and keep the prices the same. We chose the latter, as we felt it better serves our existing and new customers. We were able to do this by changing our technology stack to continue to be sustainable long term without continuously increasing prices across the board.
Looking for some Laravel Tips? Check out Jack's Laravel Tips section here.
You might also enjoy reading:

BIO
Jack Ellis, CTO
Recent blog posts
Tired of how time consuming and complex Google Analytics can be? Try Fathom Analytics: