

Building our Google Analytics Importer
technical Jack Ellis · May 15, 2023We’ve just launched our Google Analytics Importer. It’s not for just Universal Analytics, which is being killed in two months (July 1, 2023), but it imports data from GA4 too. And a big feature release wouldn’t be complete without a technical journey on how we built it.
Under Pressure
Customers have been asking for the ability to bring their Google Analytics data into Fathom for years now. And for a long time, we focused on our platform rather than Google’s data.
But when Google announced that they were killing Universal Analytics, their main analytics product, we no longer had a choice; we had to help people get their data out of there.
We began working on our solution in 2022. I will share all the details here, from what went wrong to how we absolutely smashed it when building this importer.
Data Structure
In 2022, we were convinced we would have one Import per site, which meant that we’d have to make customers authenticate with Google multiple times for each site they have. But after building it this way, we realized how awful this was and pivoted to something better. After all, while we have customers with less than five sites, we also have customers with hundreds of websites (e.g. agencies), and asking them to Oauth with Google 100+ times would feel like abusive behaviour.
The data structure we ended up on was as follows:
Import
This belonged to a user’s account, not their site, which allowed us to get creative with the Import. You would authenticate once with Google; per Import, we’d encrypt and store the OAuth data with the Import, and then you’d create “children” (ImportMaps) for the Import.
ImportMap
You could create as many ImportMaps per Import as you like, which was important. You want to import 200 sites in one Import? Go ahead. And then, within each import map, you could configure the target site, Google property, view, destination (in Fathom) and the domain you want to use in Fathom.
This structure meant that we could offer a simple table within the Import.
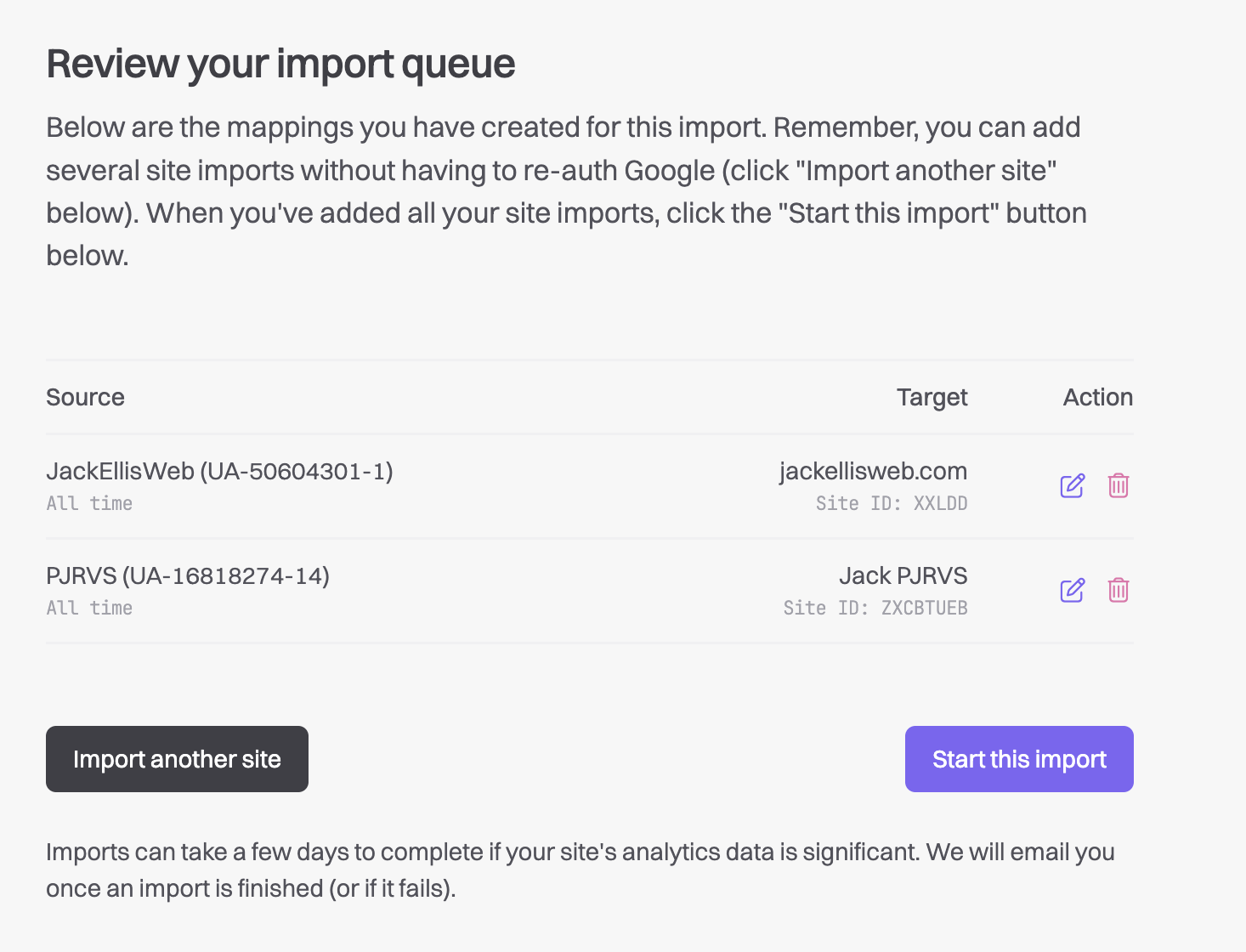
This data structure proved to be a huge win when launching, and I’m so happy we made this decision.
You have a job to do
Initially, we would queue up “jobs” in the database and manually dispatch them via a cron job, allowing us to centrally rate limit the jobs we dispatched. Long story short, the reason for this was that we were worried we’d have big customers who would come in, use up our Google API allowance and then block smaller customers from running their imports. For some reason, we thought cron jobs would be our saviour.
In the end, we built the system entirely with jobs. And we broke it up into “sub-jobs.” So once you start your Import, we call $import->start(), which then dispatches StartImportMapJob for each Import.
Within the StartImportMap job, we load the Universal Analytics or GA4 property. We then extract the timezone and the date you created your Google property, and we dispatch the following jobs:
- ImportBrowsersJob
- ImportCountriesJob
- ImportDeviceTypeJob
- ImportPageviewsJob
- ImportReferrerJob
- ImportSiteJob
- ImportUTMsJob
Each job is responsible for its own dimension. We had initially tried to do GROUP BY pathname, browser, device, referrer, country, utm_campaign, but Google’s API wouldn’t allow it, so we had to settle for broken-up data. Ultimately, most people didn’t care, as people typically look at their historical data as a whole or want to see how a page/referrer performed over time, so this worked great; it just meant we couldn’t filter the data.
And each job extends ImportJobBase, where we have a core handle set-up:
// If the Import has failed, or been cancelled, stop.
if ($this->hasBeenCancelled()) {
return;
}
// Run the report.
$report = $this->runReport();
// If there is no next page token, this is the last page.
if ( ! isset($report->nextPageToken)) {
$this->lastPage();
} else {
// Dispatch next page
self::dispatch($this->importMap, $report->nextPageToken)->delay(now()->addSeconds(5));
}Let’s talk about each piece.
$this->hasBeenCancelled()
We needed a way for the user to cancel a running import. We hated the idea of a user making a mistake and having to wait until the Import was done, as that would use up external API requests, waste their time and frustrate them. So with this hasBeenCancelled() check, every single time one of the above jobs runs, it ensures that both the ImportMap and Import status are set to “in_progress.” If they’re not, it doesn’t run. ImportMaps aren’t cancelled by the user, only Imports, but ImportMaps are marked as failed if any jobs have issues. We decided to kill the Import if any maps had issues rather than trying to import some but not the others.
$this->runReport()
In this area, each job had its own definition. We used a Facade called AnalyticsImporter, which automatically chooses a GA4 driver or Universal Analytics driver based on the ImportMap settings. And then, we’d send the various metrics, dimensions, date range, etc. and process the returned data. Once that was done, we’d insert the rows via $this->insertRows().
$this->lastPage()
We would call this method when there were no additional pages to process. Otherwise, the job would be dispatched again to load more data
Hidden: $this->insertRows()
This method is beautiful, and here’s what it does:
- It performs an atomic lock on the Import lock key (which is
import-lock:$this->uuid). - It checks to see if the import or import map has been cancelled. If it has been cancelled, the job ends
- If we’re good to keep moving, we open up a database transaction and chunk our LazyCollection into 10,000 rows per piece. We then loop through the chunks and insert them into a table called
pageviews_import.Yes, you’re right; this is a “holding table,” as we don’t want to have half-complete imports entering our main pageviews table at any point - And then the job is complete.
The biggest weakness of the insertRows() method is that if it attempts to grab a lock but can’t get it within 180 seconds, it will release the entire job. This means it would have to do the Google API hit again. We originally had this lock waiting 30 seconds, and that did cause some issues, but by waiting 180 seconds, things are working great.
Here’s the code for insertRows()
try {
// Wait 180 seconds to try and acquire the lock
Cache::lock($this->importMap->import->lockKey())->block(180, function () use ($rows) {
// If the Import has been cancelled, we don't want to insert anything
if ($this->hasBeenCancelled()) {
return ;
}
DB::transaction(function() use ($rows) {
$chunks = $rows->chunk(10000);
$chunks->each(function($chunk) {
DB::table('pageviews_import')->insert($chunk->toArray());
});
});
});
} catch (LockTimeoutException) {
// Retry the job with a 20-second delay
$this->release(20);
}We’ve seen no errors since increasing this lock wait time. If we ran into problems, we could quickly put that block() time up to 300.
Oh, and a quick note on the above code. Why do we chunk it into 10,000 rows at a time? Because we hit memory limits otherwise.
Okay, we’re dispatching these jobs; no cron jobs are used, so how will we check when an import is completed? How will we check to see if imports have been cancelled? Or if one part of the Import has failed? Especially when they could have 500 x 7 = 3,500 jobs running simultaneously.
Atomic locks
Many developers don’t use atomic locks. Or maybe I should say they’re unaware they’re using atomic locks. I am obsessed with atomic locks. When you have a ton of asynchronous tasks running, you need a way to avoid contention between tasks.
When we first went live (behind feature flags), we had a lot of fun testing this importer because we’d previously been testing locally with a single queue worker. So you didn’t have any async errors because the jobs were all run in sync.
Without atomic locks, we had the following issues:
- Which ImportMap sub-job would mark the ImportMap as complete? And then which of those would be responsible for marking the Import as complete?
- Imagine if I’m inserting into
pageviews_importin one job, but we’ve just had a CancelImport job run, which has emptiedpageviews_import.And then the insert intopageviews_importfinishes, but the jobs all finish up (since the job is cancelled, see the$this->hasBeenCancelled()job above), and we’re left with orphaned data in pageviews_import because the cancel job has already run it’s wipeData() command. Yikes. - When checking if the ImportMap is complete, we’d check our model’s total “tasks_completed” property. There were situations where one task would be complete, but another wouldn’t. Then the other task would complete JUST before the other task updated the tasks_completed property, and you got into this race condition, and the Import would just stay in limbo.
Our journey with atomic locks was incredible, and our importer is unbelievably resistant and fault tolerant.
Here’s how we use atomic locks:
WithoutOverlapping
We use job middleware WithoutOverlapping($this->importMap->uuid, 45). Although you don’t see it here, this exists on the ImportJobBase middleware class. So when ImportBrowsersJob extends that class, it will have the key of ImportBrowsersJob:$this->importMap->uuid or similar. So we’re allowing multiple import types to run per ImportMap, but we’re not allowing a single import map to have multiple ImportBrowsersJob, ImportDevicesJob, etc., jobs running simultaneously.
Failed Jobs
We use an atomic lock within each importer job’s failed() method. It locks on the Import lock key and will set the Import and ImportMap status to “failed.” We lock on the import key here because if multiple import maps fail simultaneously, we want to avoid triggering our ImportObserver to fire multiple failed emails to the user. If we locked on just ImportMap’s lock key, as we did before I changed it ten seconds ago, we would risk sending multiple failed emails to a customer. Super rare chance of this happening? Sure, but you want to cover it.
Inserting rows (and cancelling imports)
When inserting rows, we lock on the Import lockKey(). Why do we do this? The first reason is that we do a “has this been cancelled?” check, as we don’t want to insert data for something cancelled. And that brings on the second reason. When we cancel an import (), a task we run while the Import is still running, we delete the WIP data. We don’t want to delete the WIP data and then have a random job insert more data… Because then our system thinks it has cancelled it, but it hasn’t.
Here, let’s look at the code.
CancelImportJob handle()
if ($this->import->status == Import::STATUS_CANCELLED) {
return ;
}
Cache::lock($this->import->lockKey())->block(30, function() {
DB::transaction(function () {
$this->import->status = Import::STATUS_CANCELLED;
$this->import->save();
$this->import->maps()->update(['status' => ImportMap::STATUS_CANCELLED]);
$this->import->wipeData();
});
});insertRows Look at the code above (search for insertRows), and you’ll see we lock on the import key.
This prevents us from inserting data after a cancellation has happened. Because if we grab the lock on the importRows before the CancelImportJob has a chance to grab it, we insert the data into pageviews_import. But the CancelImportJob will grab it within 30 seconds (or retry) and then remove that data.
And then if the CancelImportJob completes RIGHT BEFORE the insertRows method is called, the insertRows grabs the lock and checks the status of the Import (see above, it would be marked as cancelled)
While I’m sure you’re following along, you can see why this is somewhat fiddly. It took some time for us to get the perfect set-up of locks, but the level of resilience it adds to our importer is off the charts. At the time of writing, we haven’t had a single import failure since we got on top of the locking here, and we’ve imported over 3 billion pageviews from thousands of import jobs at the time of writing.
Keeping things fast
When we originally built the system, we hit Google’s Management API to load information about properties on every page load. This was slow and wasn’t going to work for us, so we moved to caching.
But then we also did additional information lookups (timezone, created at date) in the loop. We did this to somewhat “be prepared” ahead of time, but larger sites led to rate limit hits because the fetches were being done in the loop.
We moved this additional lookup to the StartImportMapJob(), but we then hit the rate limit again. Because if you had 20 import maps in your Import, and we then hit Google’s API 20 times in less than a second, Google hit us with a rate limit, and your Import wouldn’t work.
We solved this by applying a WithoutOverlapping() atomic lock with a 2-second delay. In each StartImportMap job, we perform the request to Google for the additional data, update the ImportMap model, and then dispatch ImportBrowsersJob, ImportCountriesJob, etc., with the data already loaded.
Writing tests for this
We weren’t comfortable mocking Google’s responses at an HTTP level since we used their SDK for that. Instead, we had a “wrapper” around the data Google returned, allowing us to fake and work with that test data.
$this->testResponse = new AnalyticsResponse(null, 2, [
new AnalyticsResponseRow([
AnalyticsImporterDimensions::DATE->value => '20200101',
AnalyticsImporterDimensions::PATHNAME->value => '/test',
], [
AnalyticsImporterMetrics::PAGEVIEWS->value => 1,
AnalyticsImporterMetrics::UNIQUES->value => 1,
AnalyticsImporterMetrics::ENTRANCES->value => 1,
AnalyticsImporterMetrics::BOUNCES->value => 1
]),
new AnalyticsResponseRow([
AnalyticsImporterDimensions::DATE->value => '20200102',
AnalyticsImporterDimensions::PATHNAME->value => '/test2',
], [
AnalyticsImporterMetrics::PAGEVIEWS->value => 5,
AnalyticsImporterMetrics::UNIQUES->value => 5,
AnalyticsImporterMetrics::ENTRANCES->value => 5,
AnalyticsImporterMetrics::BOUNCES->value => 5
]),
]);My big lesson
In late 2022, we had so many things come up. And I had delayed this feature because I was busy, and we didn’t know how to apply rate limiting. And this was some psychological baggage I had. After all, we’ve been attacked before, and I always consider malicious behaviour when building things.
I learned I should’ve moved this to a test environment sooner. Sure, we didn’t have an answer for rate limiting, but testing ended up taking a long time because we tested many sites, had to account for data issues from Google (yes, we obsessed with making sure your data import was perfect) and we could’ve done this last year.
Conversely, this lesson has to be balanced by saying that the 2022 version of the Import wasn’t anywhere near as good as what we have now. So while the lesson is “ship and test faster,” I also know that great things take time to build. But we could’ve got here sooner had we shipped to testing sooner.
Happily ever after
We launched this feature, and it was a huge success. No, seriously, I’m not exaggerating here. People were so happy, they noticed all of the small things we perfected, and we received so many tweets & emails about how fast & easy it was. This project was one of our most successful, and I’m so proud of the team.



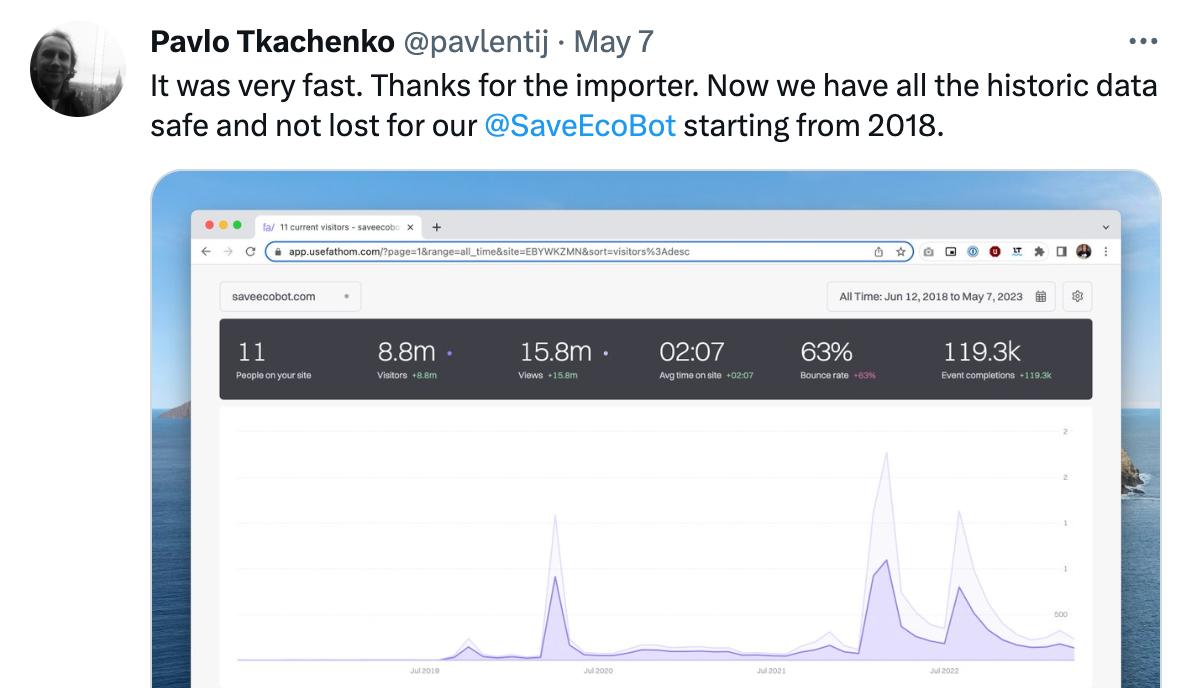
Any thoughts, abuse or questions? Click here
You might also enjoy reading:

BIO
Jack Ellis, CTO
Recent blog posts
Tired of how time consuming and complex Google Analytics can be? Try Fathom Analytics: